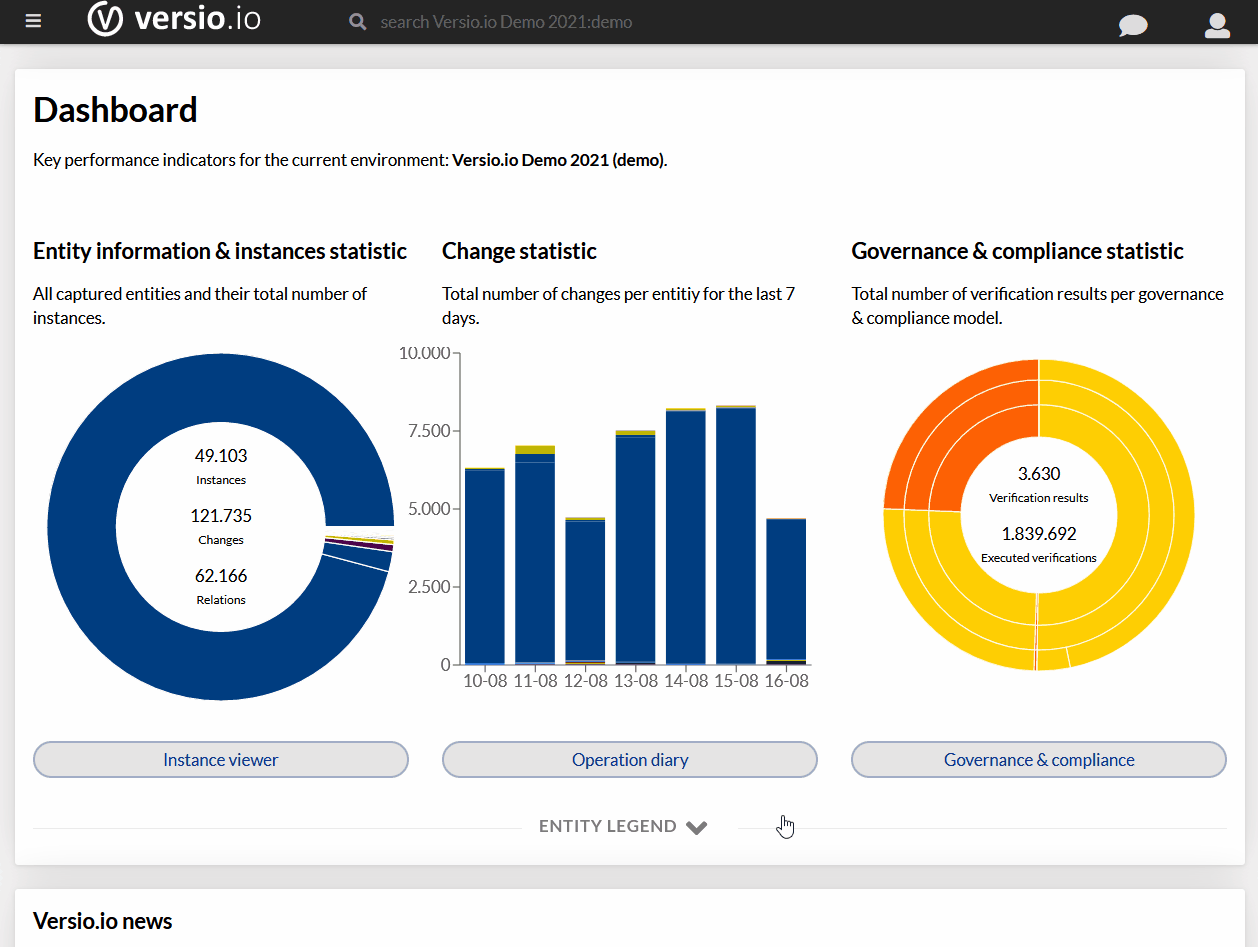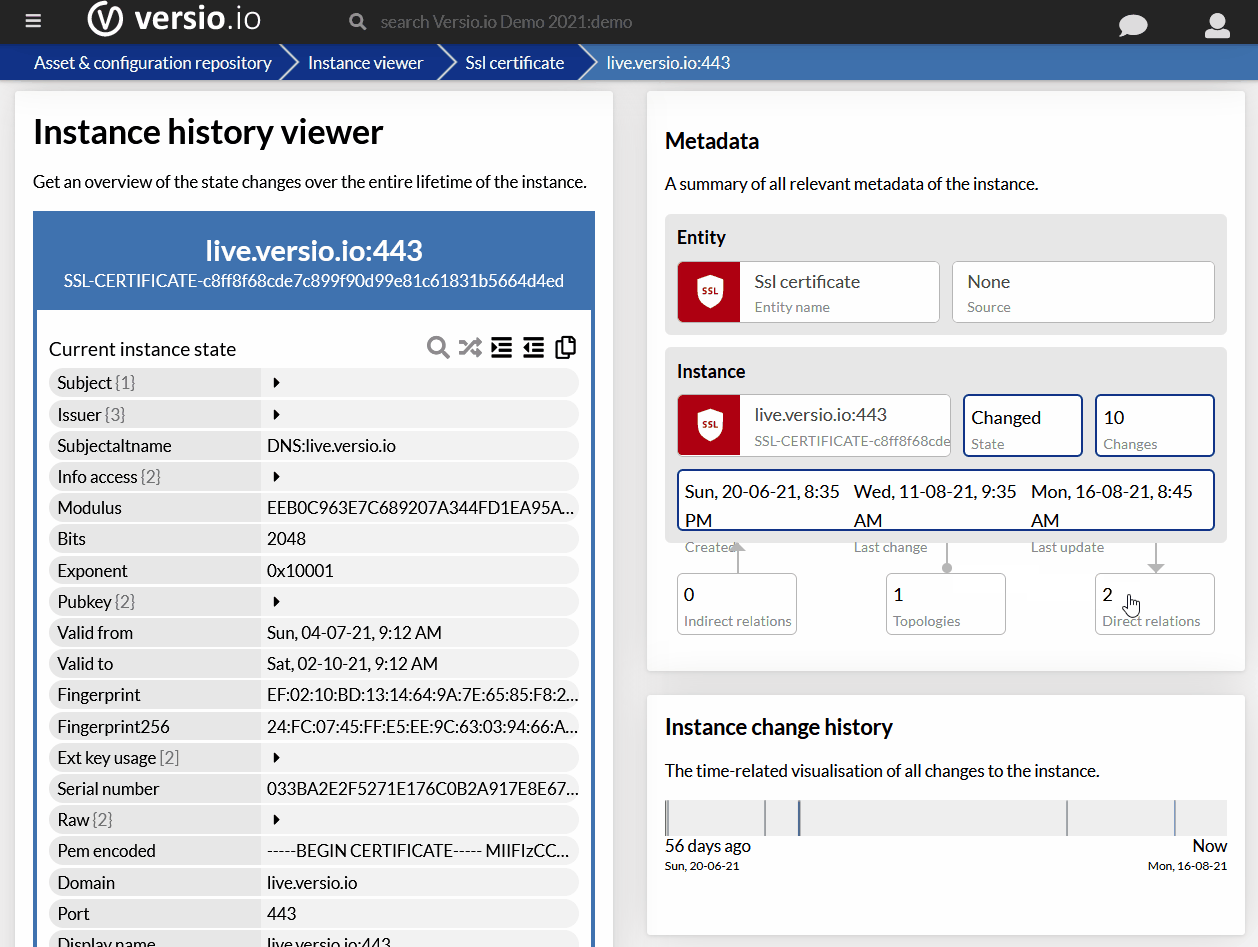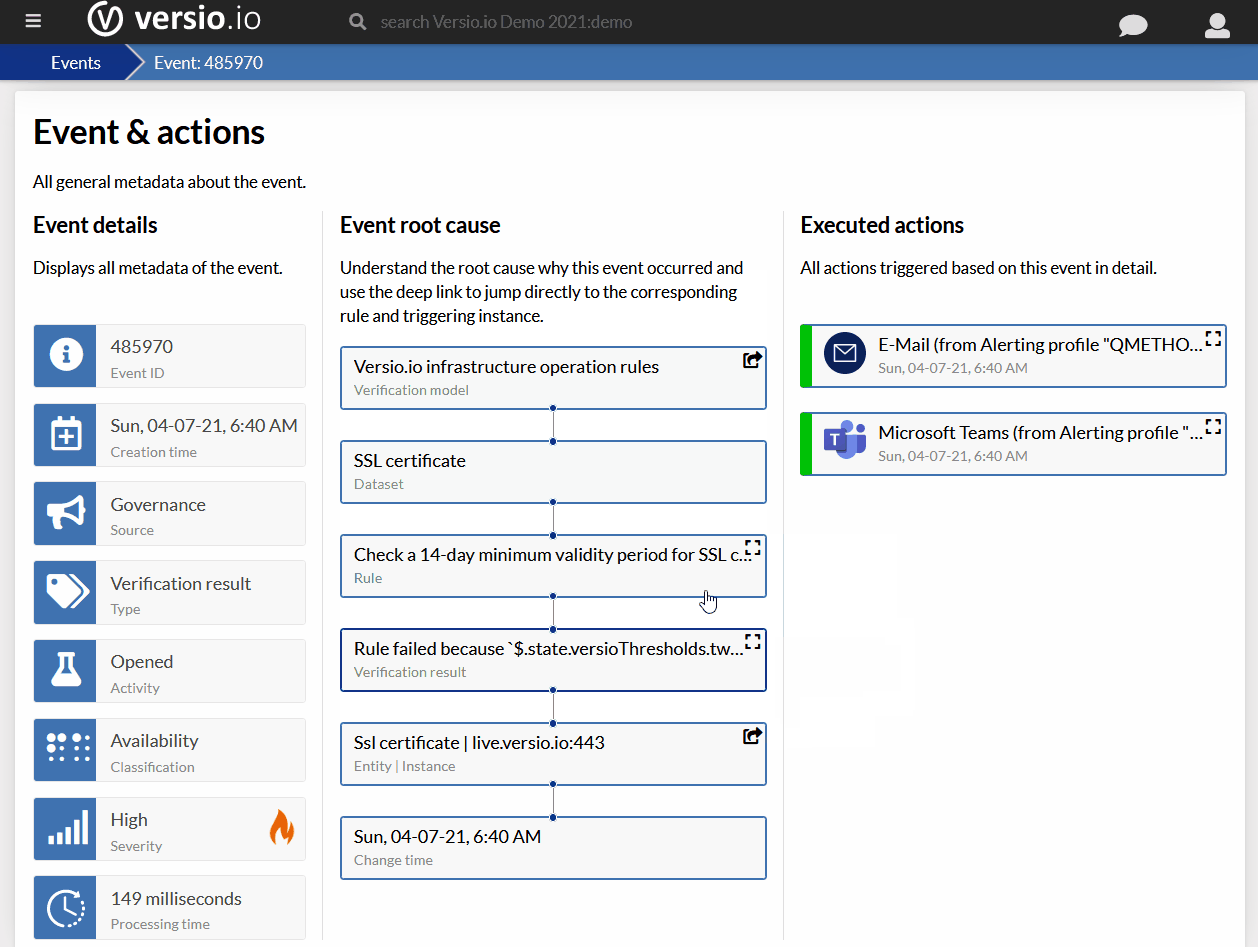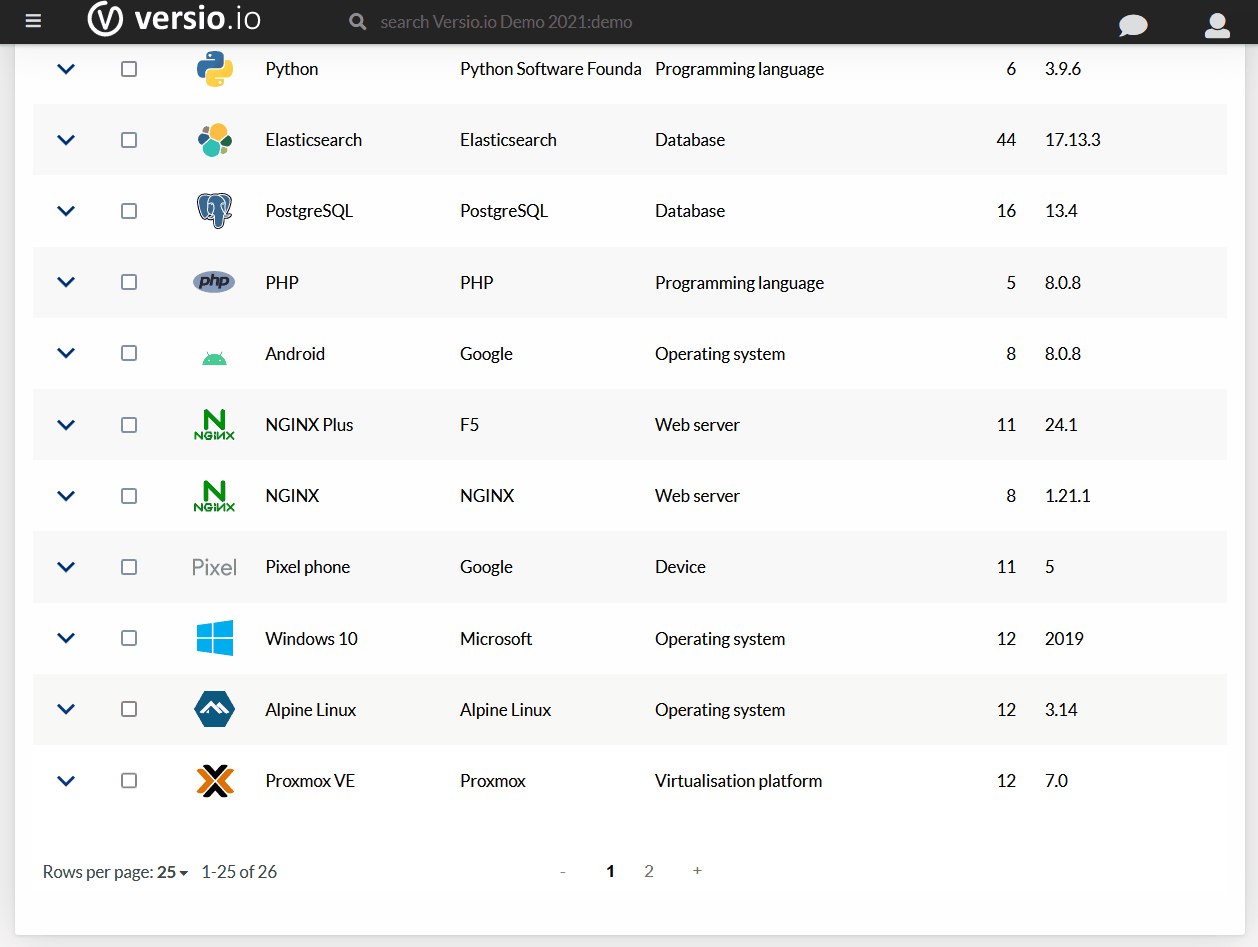
Większość dostępnych na rynku rozwiązań monitorujących, wciąż opiera się na „progach lub liniach bazowych” w celu identyfikacji głównej przyczyny wykrytych problemów.
Wobec bardzo dynamicznych architektur usług oprogramowania, takich jak mikroserwisy i funkcje bezserwerowe (np. AWS Lambda), niemożliwe jest na dłuższą metę efektywne stosowanie podejścia „manualnego”, które wymaga ciągłego definiowania i strojenia warunków, progów, alertów, itd. Nawet nowoczesne sposoby monitorowania takich środowisk (na przykład automatyczne bazowanie) nadal wymagają konfiguracji „ręcznej”.
Podejście funkcjonujące w oparciu o tzw. linie bazowe wciąż powoduje niewielki odsetek błędnych alarmów. Oznacza to, że liczba tzw. false-positives jest wprost proporcjonalna do liczby monitorowanych komponentów.
Załóżmy, że OneAgent Dynatrace działający na pojedynczym hoście zbiera średnio około 500 różnych metryk, np. dane procesora, pamięci, sieci, procesów i usług itp., w zależności od wykorzystywanych technologii. Jeśli wynik bazowy będzie zawierał tylko 0,1% błędnych alarmów na metrykę w skali roku, to dany host będzie powodował 50 błędnych alarmów. Jeśli pomnożymy to przez 1000 hostów, otrzymamy 50000 błędnych alarmów rocznie – duże uproszczenie, ale obrazuje ryzyko, o którym chcemy napisać.
To wyraźnie pokazuje, że „wartości wyjściowe i progi” nie są najlepszymi rozwiązaniami do wskazywania źródeł problemów w chmurach sieci korporacyjnych (tzw. enterprise cloud).
Zautomatyzowana analiza przyczyn źródłowych – „bez progów lub linii bazowych.”
Dynatrace wprowadził pierwszą platformę do analizy oprogramowania, opartą na „silniku AI”, która w pełni automatyzuje wykrywanie anomalii i co najważniejsze, automatyzuje identyfikację źródeł przyczyn awarii.
W ciągu ostatnich czterech lat rozwiązanie „Dynatrace AI” dowiodło, że w pełni zautomatyzowana analiza problemów jest jedynym właściwym podejściem, szczególnie w wysoce dynamicznych środowiskach mikroserwisów, w których podejście manualne jest wręcz niewykonalne.
Najnowsza wersja Dynatrace udostępnia kolejną generację analizy przyczyn źródłowych opartą o AI – całkowicie nową, ulepszoną technologię automatyzującą identyfikację źródeł awarii.
Zamiast polegać na „zdarzeniach i progach”, wykrywanie niepewnych metryk jest realizowane przez analizę rozkładu wartości danych. Jeśli aktualny rozkład pomiarów metrycznych znacznie odbiega od zaobserwowanego historycznego zachowania metryki, dany składnik jest oznaczany jako niebezpieczny, nawet jeśli nie osiągnięto progu alarmowego.
Przewaga takiego podejścia do automatycznej analizy przyczyn źródłowych nad ręczną lub półautomatyczną (bazującą na korelacjach) okazuje się tym większa, im więcej danych jest zbieranych i analizowanych.
Inteligentniejsze, bardziej precyzyjne ustalenia przyczyn źródłowych.
Analiza przyczyn źródłowych Dynatrace nowej generacji, dodatkowo poprawia wizualizację poszczególnych odkryć, takich jak zmiany w dostępności podstawowej infrastruktury.
- Analiza tzw. root-cause wprowadza większy poziom precyzji i umożliwia użycie zdefiniowanych przez klienta miar oraz zdarzeń lub danych z zewnętrznych systemów integracyjnych – to pozwala na dalszą automatyzację zarządzania IT.
- Analiza głównych przyczyn daje możliwość szybkiego sprawdzenia stanu dostępności wszystkich istotnych składników usługi w kontekście pojawiających się problemów. W sekcji, która dotyczy wskazania „głównej przyczyny”, można bez żadnej konfiguracjizobaczyć wszystkie istotne informacje dotyczące przestojów poszczególnych elementów infrastruktury.
- Nowy algorytm sztucznej inteligencji wykrywa również przyczyny bez powodowania fałszywych alarmów.
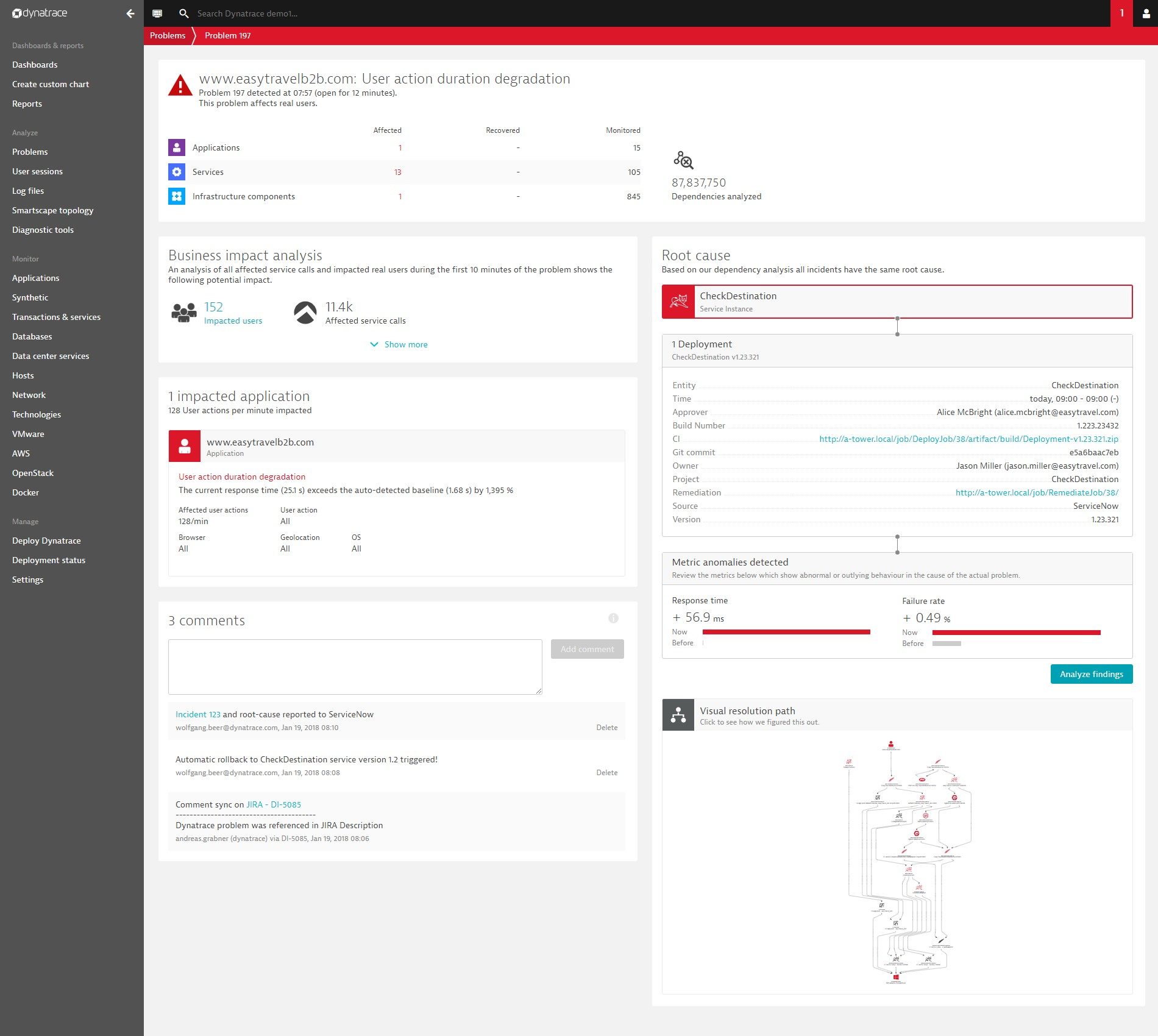
Powyżej zamieszczamy przykład w pełni zautomatyzowanej analizy przyczyn opartej na sztucznej inteligencji. Precyzyjnie powiązano tzw. zdarzenie deploymentu, które zostało przesłane poprzez REST API, ze spadkiem wydajności aplikacji.
Oto przykład nowo wprowadzonej sekcji, głównej przyczyny dostępności:
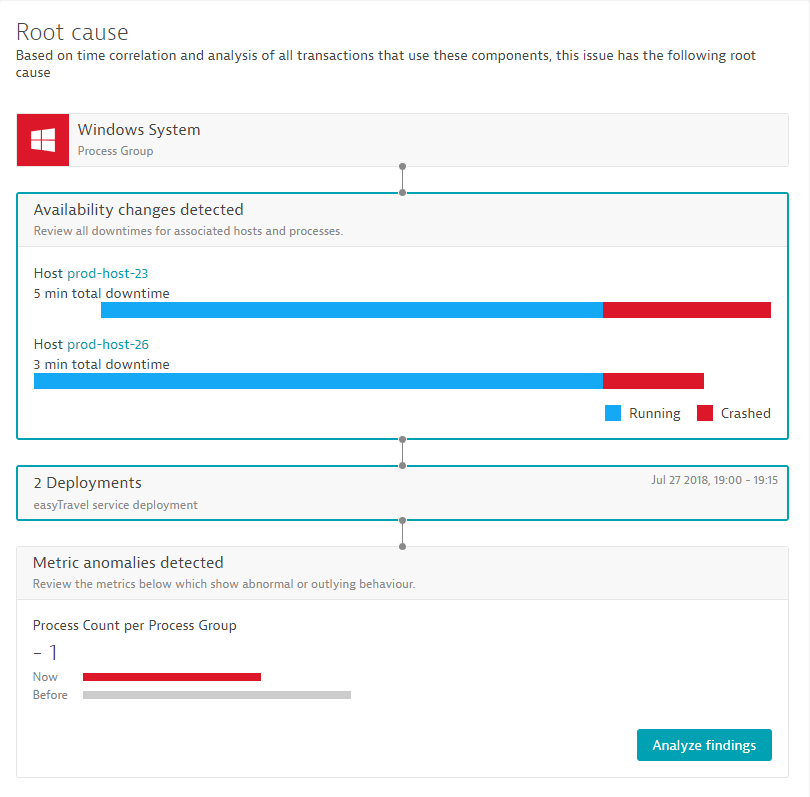
Aby włączyć silnik AI nowej generacji dla poszczególnych środowisk:
- Kliknij opcję „Problems” w menu nawigacji.
- W obrębie banera na górze strony kliknij przycisk „Switch to next generation AI engine”

Jak działa analiza przyczyn źródłowych nowej generacji.
Na dzień dzisiejszy Dynatrace OneAgent gromadzi ponad 1000 różnych rodzajów danych dla każdego monitorowanego komponentu plus wiele dodatkowych wskaźników dot. integracji z rozwiązaniami w chmurze. Poprawność działania każdego z komponentów określana jest właśnie na podstawie tych danych, zarówno z analizy automatycznych linii bazowych jak i progów.
Nowy mechanizm analizy przyczyn źródłowych Dynatrace wprowadza zupełnie inne podejście. Wykrywanie źródła problemu w złożonych sytuacjach nie jest już zależne od linii bazowej czy przekroczenia zdefiniowanego.
Za każdym razem, gdy dane zdarzenie występuje na monitorowanym komponencie, AI i algorytmy detekcji przyczyn źródłowych automatycznie analizują wszystkie transakcje na żywo – analizowany jest przebieg horyzontalny transakcji. „AI” automatycznie przechodzi do analizy, jeśli linie poziome pokazują, że wywoływana usługa jest oznaczana jako problematyczna, jak pokazano na poniższym schemacie. Przy każdym przeskoku wzdłuż linii poziomej linia pionowa technologii jest również analizowana pod kątem wystąpienia błędów, spadku wydajności, zmiany stanu na tzw. „unhealthy”.
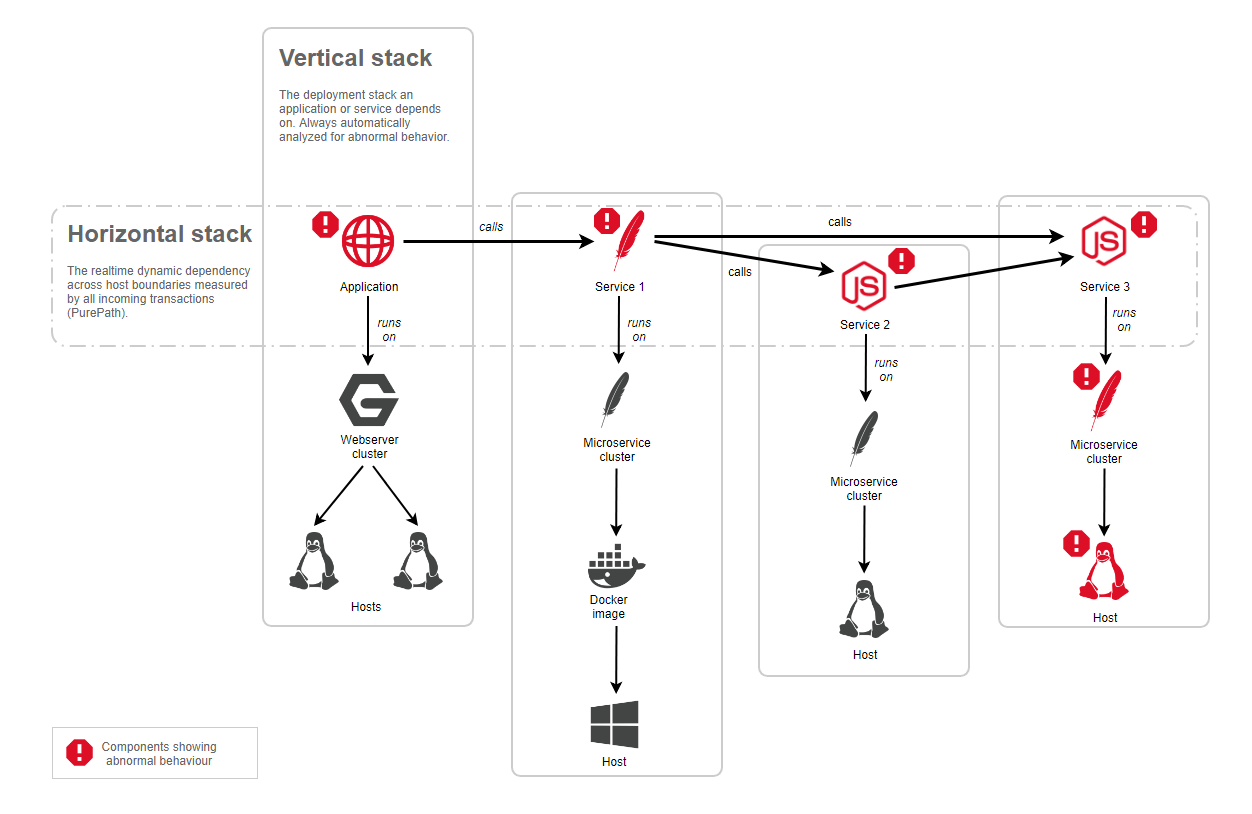
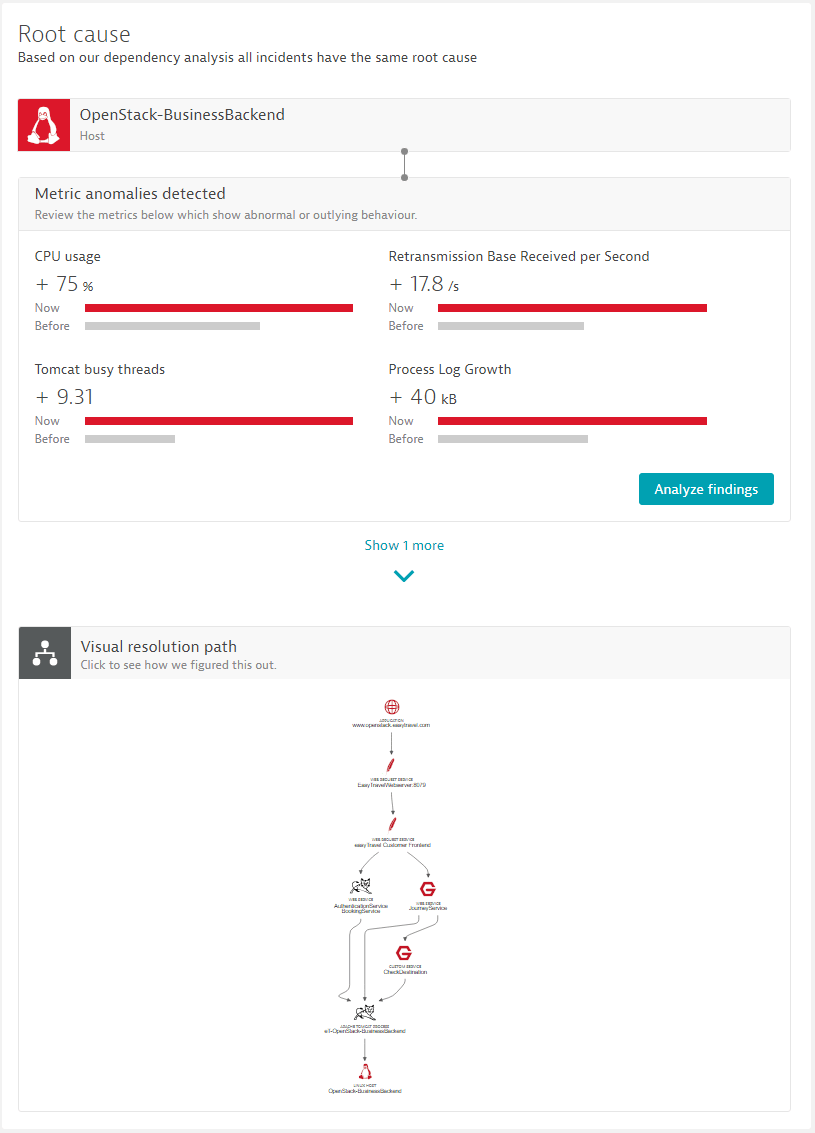
Aby poradzić sobie z wyzwaniem narastającej liczby wskaźników, analiza głównej przyczyny Dynatrace nowej generacji, automatycznie sprawdza wszystkie dostępne dane we wszystkich zagrożonych częściach. Podejrzane zachowanie wskaźników jest wykrywane przez analizowanie składników konkretnego wskaźnika z przeszłości i porównywanie go z rzeczywistym. Dlatego nowa analiza nie bazuje już na „zdarzeniach” i „progach”. Jeśli jednak „zdarzenie” lub niestandardowy próg, zdefiniowany przez użytkownika są dostępne, to zostaną one uwzględnione w procesie analizy głównej przyczyny.
Poniższy przykład ilustruje, w jaki sposób Dynatrace wykrywa przyczyny źródłowe bez wywoływania błędnych alarmów. Analiza stwierdza, że problematyczny serwer pokazuje wzrost użycia CPU o 75%, i dodatkowo mamy zwiększoną liczbę zajętych wątków po stronie Tomcat’a.
Podsumowanie
Dzięki wbudowanej analizie przyczyn źródłowych, nowa platforma Dynatrace upraszcza proces detekcji problemów – udoskonalono mocne strony rozwiązania i w pełni automatyczne określanie przyczyn problemów.
Analiza wpływu na biznes i analiza anomalii w oparciu o „PurePath” pozostają niezmienione, a ulepszenia, takie jak wykrywanie anomalii metrycznych, zdarzenia niestandardowe i niestandardowe metryki, zostały efektywnie zintegrowane i korzystają z dobrodziejstw AI i platformy Dynatrace.
Ulepszenia te po raz kolejny przesuwają granicę automatycznej, opartej na sztucznej inteligencji analizy przyczyn źródłowych.