Poprzednio walczyliśmy z opóźnieniami wprowadzanymi przez sieć. Wtedy akurat były one po stronie serwera, a serwer gdzieś w odmętach Internetu, więc nic nie dałoby się z tym zrobić, ale gdyby to była twoja lokalna sieć czy centrum danych, sytuacja nabrałaby zupełnie innego znaczenia, bo wiadomo, do kogo iść z takim problemem.
W tym odcinku zajmiemy się identyfikacją problemów spowodowanych przez klienta. Nie takiego awanturującego się, ale stację kliencką twojej aplikacji. Tak, tak, obserwacja sieci i analiza protokołów pozwala na rozpoznanie takich sytuacji.
Wolny transfer
Wyobraź sobie, że użytkownik narzeka na koszmarnie wolne pobieranie pliku z serwera. Sytuacja nie jest permanentna, ale przezornie masz na serwerze zainstalowanego tcpdumpa, którego użyjesz do złapania ruchu. Gdyby to było niemożliwe, zawsze możesz zainstalować Wiresharka i złapać ruch ze stacji użytkownika. Pamiętaj, że jeżeli używasz Windows, musisz mieć WinPcap (drivery, bez których Wireshark nie zadziała) i musisz zezwolić WinPcapowi na dostęp do karty sieciowej. Jeśli serwer lub klient to Linux/Unix, instalacja tcpdumpa wystarczy, jeśli nie ma go domyślnie w dystrybucji.
Załóżmy, że łapiemy dumpa na serwerze, tcpdump jest już zainstalowany, więc jedyne, co musimy zrobić, to go uruchomić na konsoli.
tcpdump -i eth1 -s 0 -w slow-download.pcap
Powyższe polecenie włączy zrzucanie ruchu z interfejsu eth1, zapisując pełne segmenty (z payloadem, ale możesz ograniczyć ilość zapisywanych danych, jeśli interesują cie nagłówki) i zapisze to do pliku slow-download.pcap. Możesz też użyć opcji -s 65535, co powinno zapisywać 65kB segmenty. Niektóre wersje tcpdumpa nie akceptują –s 0. Pamiętaj, że musisz wybrać interfejs, na którym będziesz łapać pakiety. Jeśli nie wiesz, jak się nazywają, zawsze możesz skorzystać z opcji -D, która wyświetli listę dostępnych interfejsów sieciowych.
tcpdump -D
Żeby zakończyć łapanie ruchu, naciśnij Ctrl+C albo w linii poleceń ustaw czas i/lub wielkość pliku pcap, po którym zakończy się działanie tcpdumpa.tcpdump -c 1000 -> zakończy łapanie ruchu po 1000 pakietów
Tcpdump może być bardziej precyzyjny, żeby ograniczyć wielkość zapisywanego pliku. Wyrażenia filtrów pozwalają określić:
- protokół
tcpdump tcp - port lub zakres portów
tcpdump port 80<br>tcpdump portrange 21-23 - adres źródłowy lub docelowy, albo adres hosta bez względu na kierunek
tcpdump src 192.168.88.21<br>tcpdump dst 192.168.88.21<br>tcpdump host 192.168.88.21
Dokładny opis wszystkich opcji znajdziesz w man pages.
Alternatywa dla Windows
Słyszałem, że spece od Windows mówią, że cały ten WinPcap i tcpdump to zbędny balast. I że jest systemowa alternatywa w postaci programu netsh. Jeśli w twoim Windows poniższe polecenie zachowa się podobnie, to jest nadzieja, że poradzisz sobie bez WinPcapa.
netsh trace help<br>The following commands are available:
Commands in this context:
? – Displays a list of commands.
convert – Converts a trace file to an HTML report.
correlate – Normalizes or filters a trace file to a new output file.
diagnose – Start a diagnose session.
dump – Displays a configuration script.
help – Displays a list of commands.
show – List interfaces, providers and tracing state.
start – Starts tracing.
stop – Stops tracing.
Przykładowe polecenie do rozpoczęcia łapania dumpa mogłoby wyglądać tak:
netsh trace start capture=yes Ethernet.Type=IPv4 IPv4.Address=192.168.88.21
Zatrzymać tego potwora można poleceniem:
netsh trace stop
Jest tylko jeden problem z netsh, a mianowicie, dump jest zapisywany w microsoftowym formacie ETL (Event Trace Log). Kiedyś do konwersji ETL na PCAP potrzebny był MS Message Analyzer, ale na szczęście Wireshark w wersji 2.2+ radzi sobie doskonale z formatem ETL.
OK, dump na serwerze złapany, teraz pora na analizę.
Transfer od strony serwera
Dump od strony serwera był łapany dokładnie w tym samym czasie, co od strony klienta, więc będziemy mogli porównać 1:1, co się działo na obu końcach tego połączenia.
Najpierw tzw. sanity check, czyli sprawdzenie, czy dump jest kompletny i nic nie wypadło w czasie łapania. Najszybciej to sprawdzisz klikając ikonę Properties.
Jeśli w twoim dumpie nie ma dziur, czyli Dropped packets, jest dobrze.

Kolejnym fajnym udogodnieniem analitycznym w Wiresharku jest coś, co do niedawna oferowały tylko komercyjne analizatory pakietów, tj. Expert analysis.
Tak, ta mała ikonka to wielka sprawa, bo zaraz po wczytaniu dumpa pokazuje, czy Wireshark zdiagnozował problemy i jakiego rzędu. Jeśli jest czerwona, to pewnie jakieś grube sprawy, jeśli żółta, to coś jest na rzeczy itd. Ale prawdziwa wartość Expert information, bo tak to się w Wiresharku nazywa, jest to, że dostajemy pogrupowane problemy z odsyłaczami do pakietów. W naszym serwerowym dumpie Wireshark nie wykrył niczego podejrzanego.
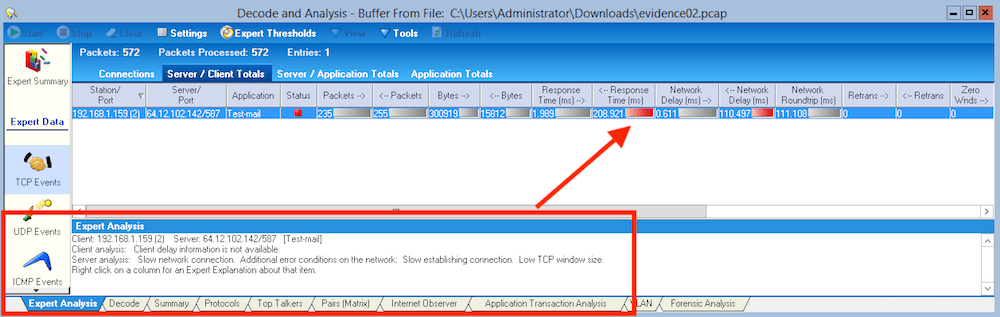
 Komercyjne analizatory pakietów robią to trochę lepiej, np. tak, jak poniżej.
Komercyjne analizatory pakietów robią to trochę lepiej, np. tak, jak poniżej.
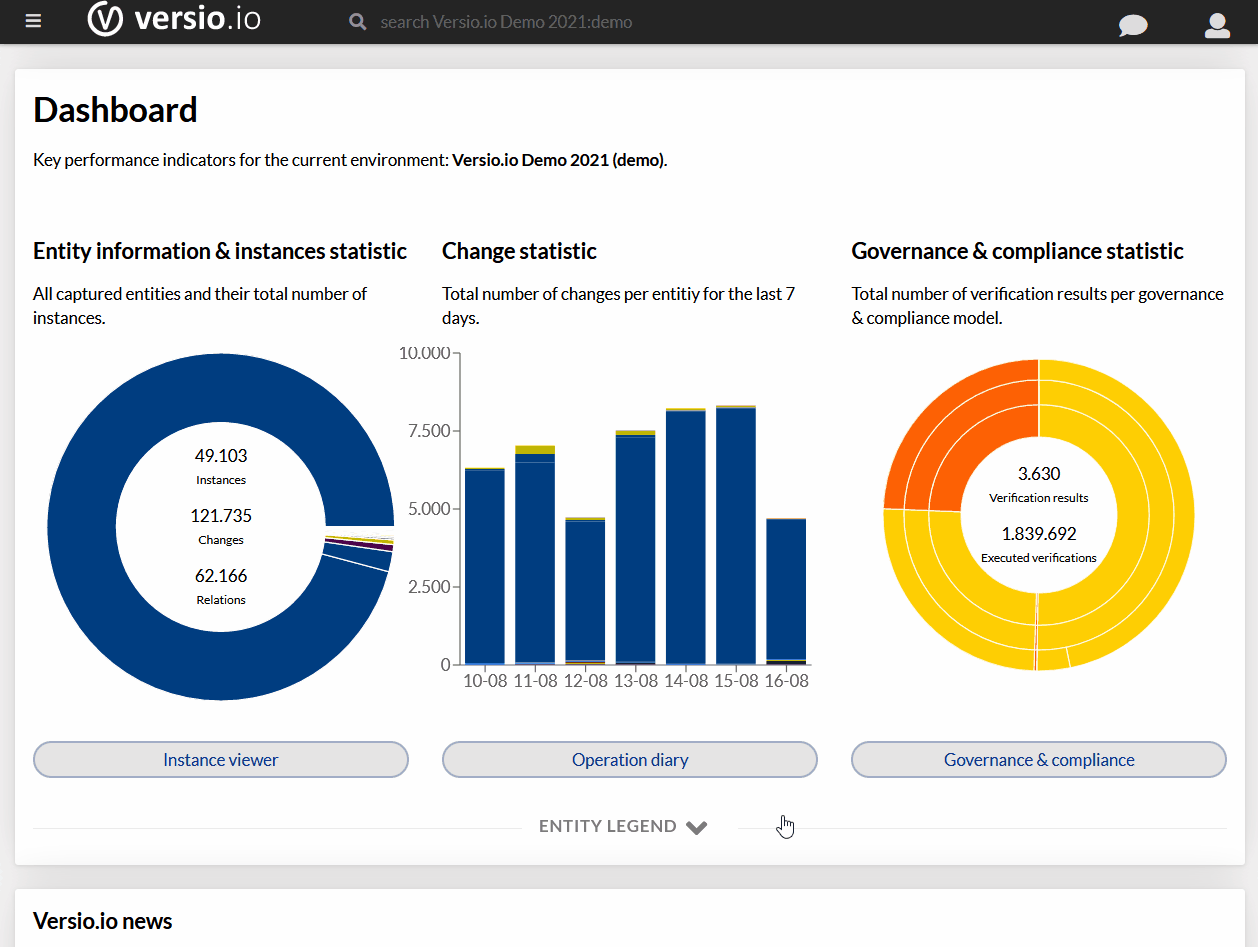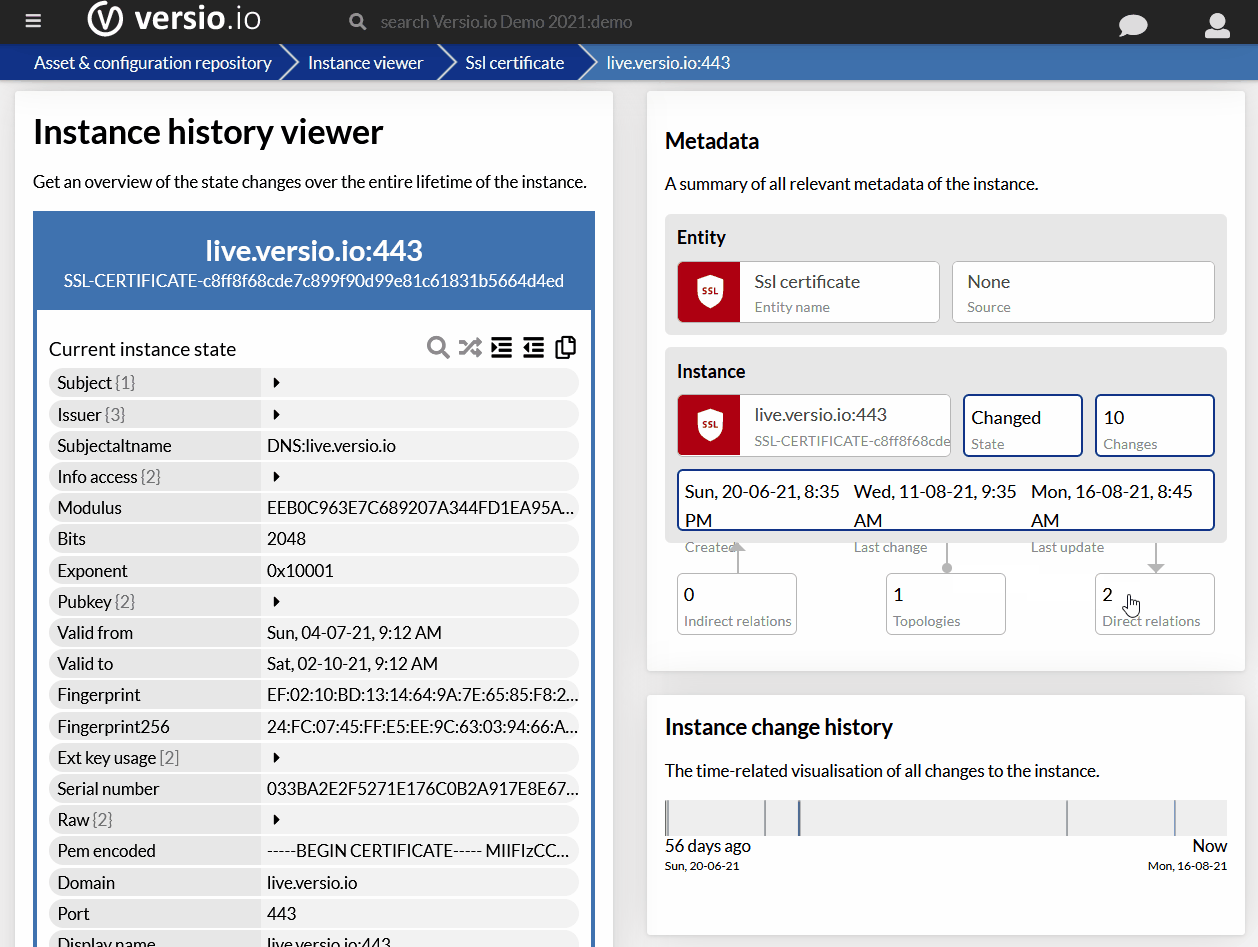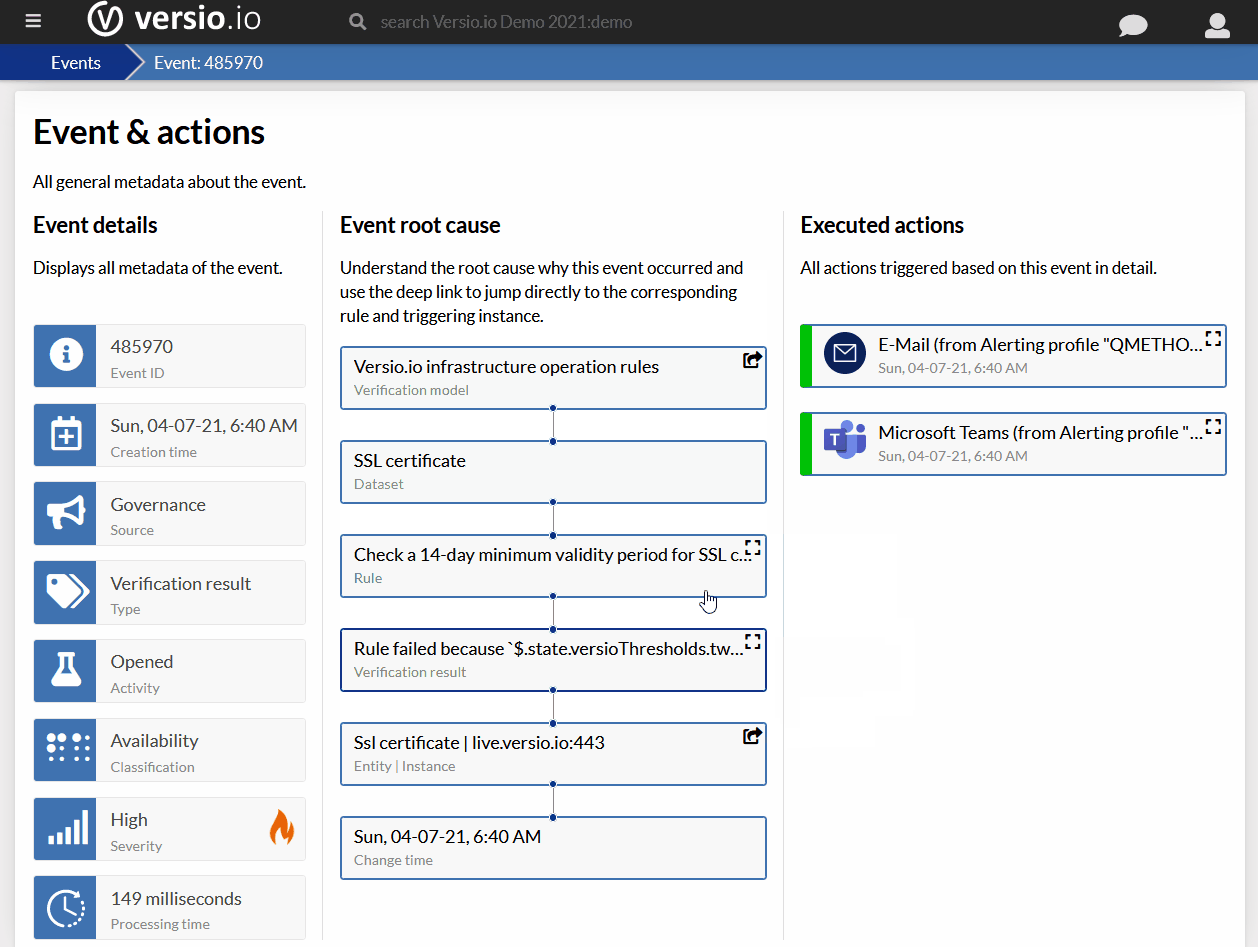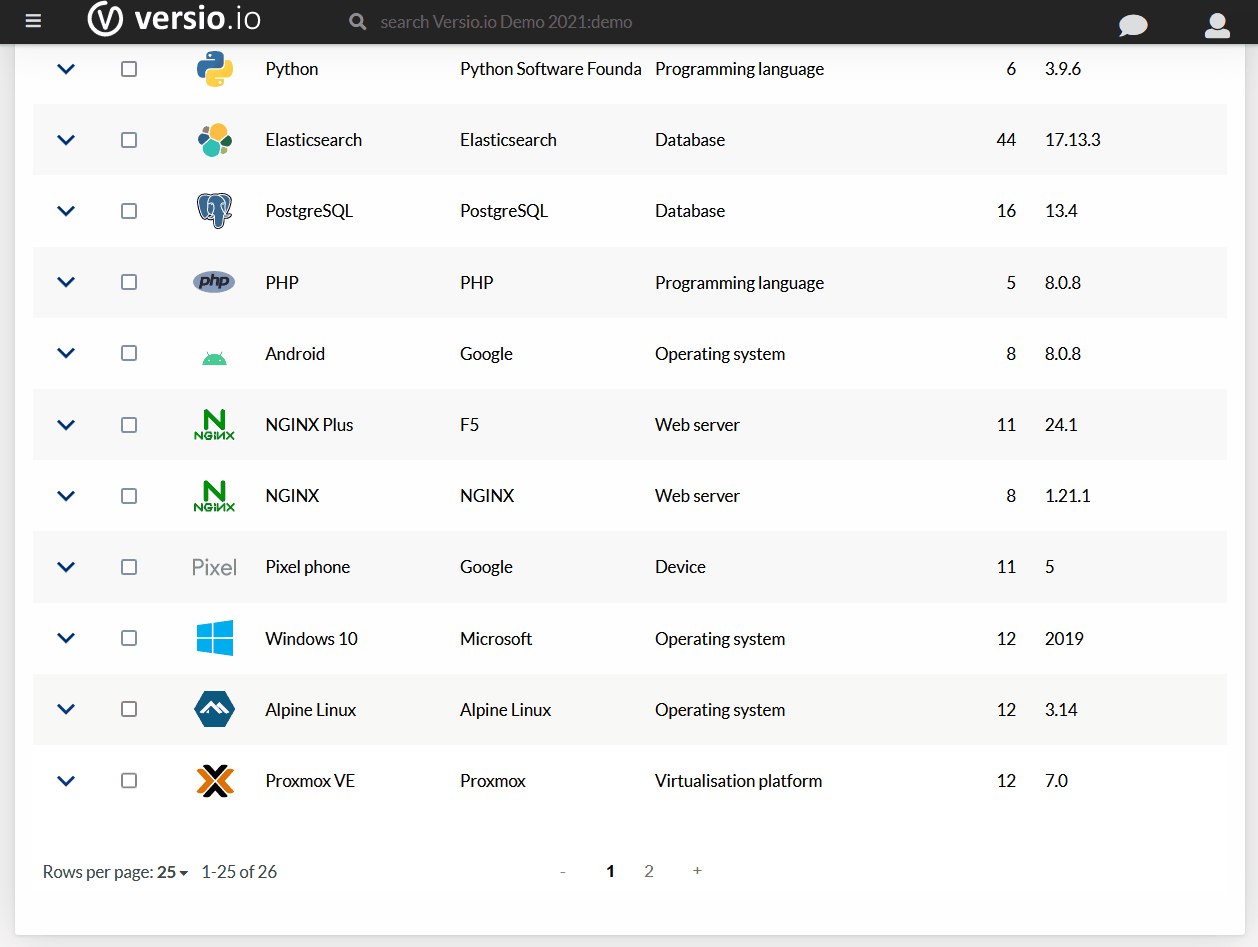
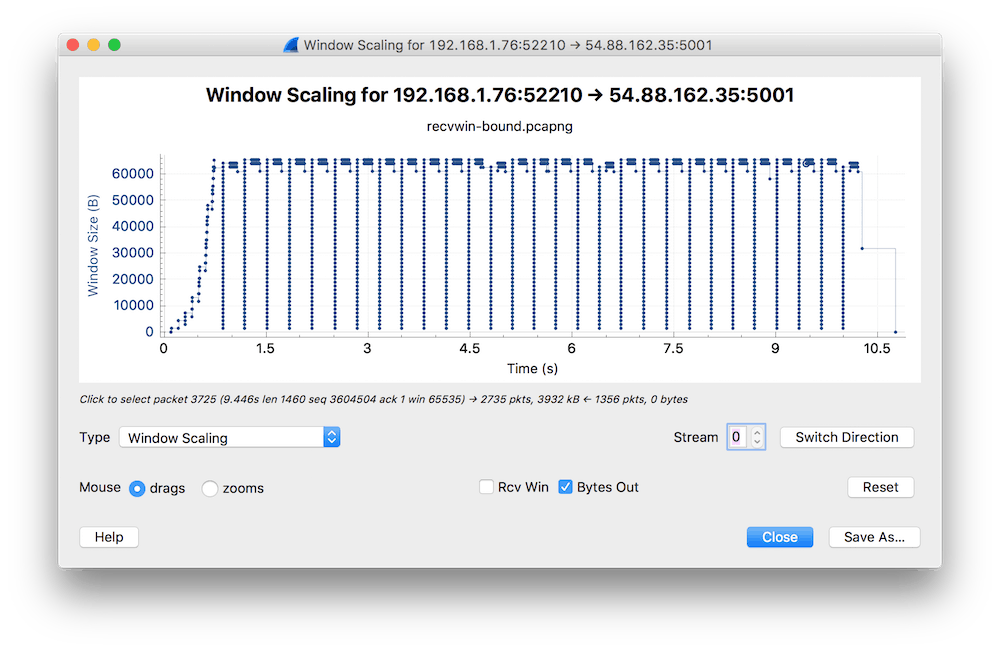
Skoro Wireshark niczego podejrzanego nie wykrył, a użytkownik zgłasza problem, to może jednak ta analiza nie jest taka dobra, jakby mogło się wydawać? Zaraz to sprawdzimy. Pamiętasz wykres RTT z części 3 tego cyklu? Ten wykres Wiresharka jest wartościowy również dlatego, że pozwala na szybkie przełączanie statystyk bez utraty kontekstu. Użyjmy go jeszcze raz, ale tym razem zobaczymy coś innego. Idziesz do Statistics > TCP Stream > Window Scaling. Jestem przekonany, że jeśli zrobisz to w swoim środowisku, nie zobaczysz tego samego, co na poniższym obrazku, ale od teraz będziesz potrafić zidentyfikować taką sytuację.
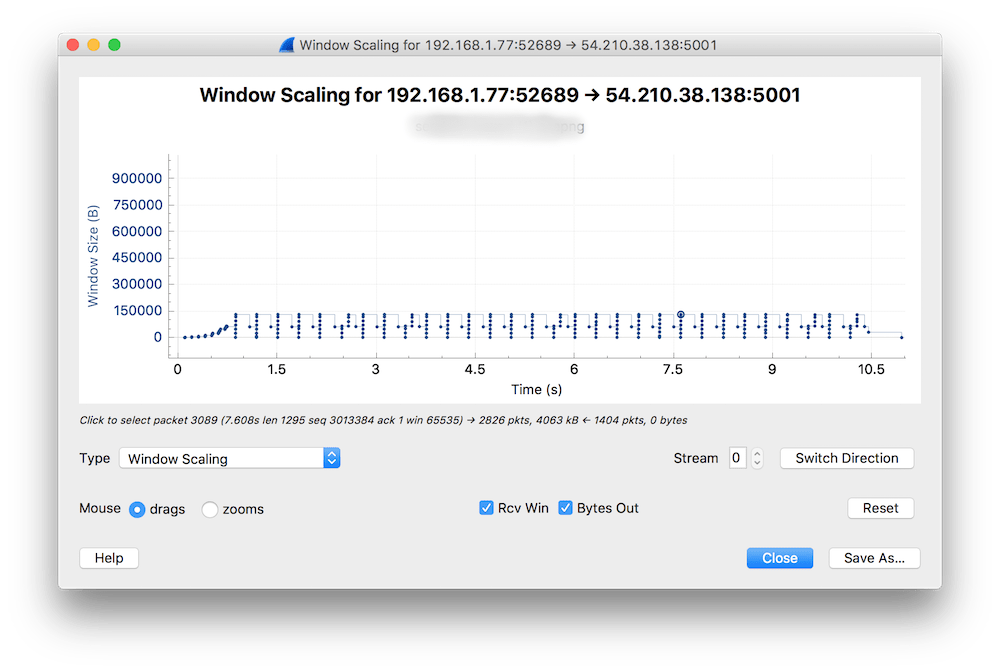 Z wykresu wynika, że przez pierwsze 750 ms serwer się „rozpędzał” i pozwalał sobie na powiększanie bufora (TCP Window). To się fachowo nazywa TCP slow start i generalnie w każdej implementacji stosu TCP działa to tak, że konwersacja startuje z niezbyt dużym TCP Window i przy każdym potwierdzeniu paczki danych (pakiet z flagą ACK) deklarowana jest większa wartość TCP Window, aż do osiągniecia maksimum. A maksimum, zależnie od OS i konfiguracji dla aplikacji może być np. 1 MB, co oznacza, że pakiety potwierdzenia (z flagą ACK) przyjdą po przesłaniu 1 MB danych.
Z wykresu wynika, że przez pierwsze 750 ms serwer się „rozpędzał” i pozwalał sobie na powiększanie bufora (TCP Window). To się fachowo nazywa TCP slow start i generalnie w każdej implementacji stosu TCP działa to tak, że konwersacja startuje z niezbyt dużym TCP Window i przy każdym potwierdzeniu paczki danych (pakiet z flagą ACK) deklarowana jest większa wartość TCP Window, aż do osiągniecia maksimum. A maksimum, zależnie od OS i konfiguracji dla aplikacji może być np. 1 MB, co oznacza, że pakiety potwierdzenia (z flagą ACK) przyjdą po przesłaniu 1 MB danych.
Ale wracając do naszego dumpa, po slow starcie zaczęło się dziać coś przedziwnego i taki stan powtarzał się wielokrotnie wg tego samego wzorca. Jeśli powiększymy fragment wykresu, to zauważymy lepiej, co się działo z wielkością TCP Window.
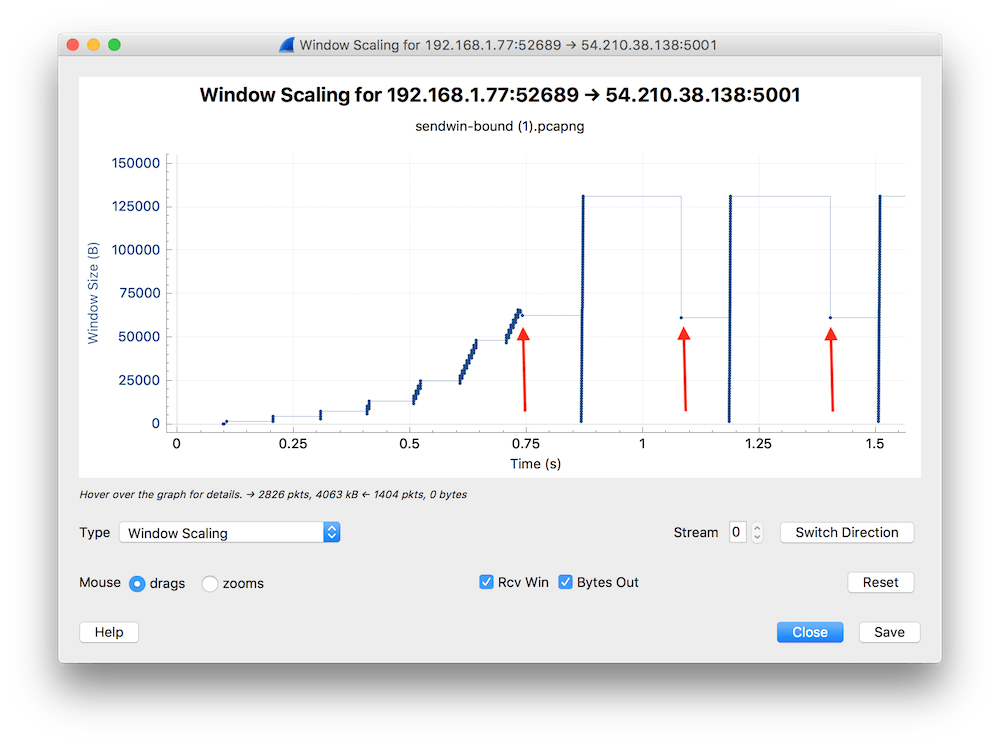 Strzałkami zaznaczyłem pakiety-anomalie. Jeśli spojrzeć na te punkty detalicznie (można kliknąć dowolny punkt na wykresie i w głównym oknie Wiresharka kursor ustawi się dokładnie na tym pakiecie), to wydaje się, że chyba wiadomo, co się dzieje.
Strzałkami zaznaczyłem pakiety-anomalie. Jeśli spojrzeć na te punkty detalicznie (można kliknąć dowolny punkt na wykresie i w głównym oknie Wiresharka kursor ustawi się dokładnie na tym pakiecie), to wydaje się, że chyba wiadomo, co się dzieje.
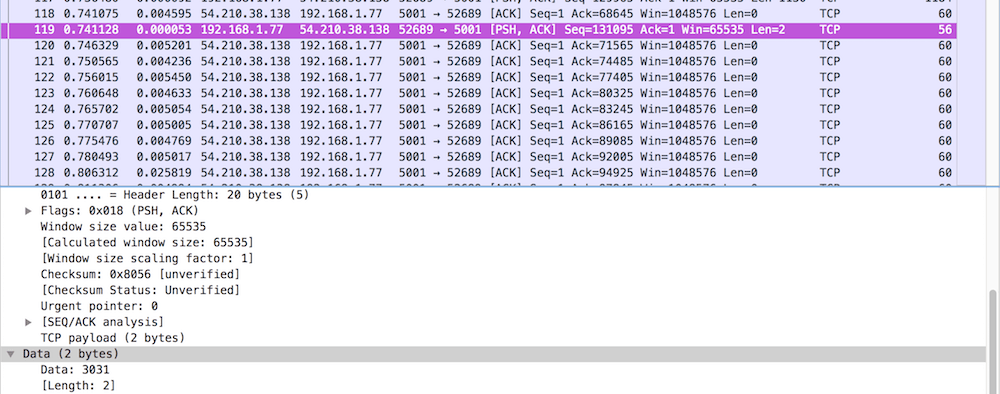
Pakiet 119 (pierwszy zaznaczony strzałką) niesie w sobie tylko 2 bajty! To jest o tyle dziwne, że poprzedzające go pakiety niosły tyle, ile się da wcisnąć w segment. Pakiet 116 miał 1460 bajtów danych (patrz pole Len w kolumnie Info), a pakiet 117 -> 1130 bajtów. Przecież do wypełnienia było jeszcze dość miejsca, żeby wcisnąć jeszcze te dwa bajty.

Mamy pierwszego podejrzanego, to aplikacja i/lub stos TCP na serwerze. Ponieważ był to transfer w protokole TCP, to trzeba się przyjrzeć w kodzie aplikacji, jak opróżniają się bufory socketów. Co ciekawe, po takim przytkaniu się buforów, deklarowana wielkość TCP Window Nie zawsze mamy dostęp do kodu i nie zawsze znamy zachowanie systemu operacyjnego, ale przynajmniej wiadomo, że to nie sieć jest winna takiemu zachowaniu aplikacji.
Żeby dopełnić obraz tego transferu, idealnie byłoby mieć dumpa ze strony klienta, bo jednostronny dowód może nie być przekonujący, a w na pewno nie jest to pełna analiza problemu.
Transfer od strony klienta
Możesz nie wiedzieć, kim był Adam Słodowy. Ale ci, którym to nazwisko nie jest obce, pamiętają, że pan Adam zawsze przypadkiem miał coś, czego każdemu normalnemu człowiekowi brakowałoby w konkretnej sytuacji. Tak i ja, jak Adam Słodowy, przypadkiem jestem w posiadaniu dumpa złapanego na komputerze użytkownika, czyli po stronie klienta. Co więcej, dumpa złapałem dokładnie w tym samym czasie. Przypadki się zdarzają ????
Otwieram dumpla klienckiego w Wiresharku i dalej jadę wg schematu:
1. Sanity check
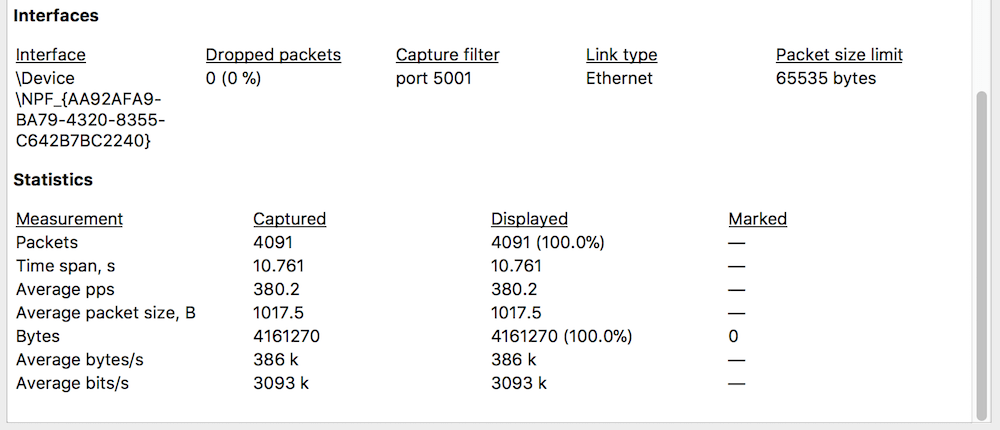
Wszystko w porządku, nic nie przepadło (Dropped packets = 0).
2. Expert information
 I tu pierwsza niespodzianka, a raczej ostrzeżenie. Wireshark podpowiada, że w dumpie są 574 pakiety wskazujące, że odbiornik (klient) miał problemy z TCP Window. Zaraz przyjrzymy się temu bliżej.
I tu pierwsza niespodzianka, a raczej ostrzeżenie. Wireshark podpowiada, że w dumpie są 574 pakiety wskazujące, że odbiornik (klient) miał problemy z TCP Window. Zaraz przyjrzymy się temu bliżej.
3. Filtr TCP problems
 Skoro Expert info podnosi alarm, warto zobaczyć, co to za problemy widać w pakietach.
Skoro Expert info podnosi alarm, warto zobaczyć, co to za problemy widać w pakietach.
Po uruchomieniu filtra TCP problems informacja z Expert info się wyjaśnia – TCP Window full. Pakiety tego typu to aż 14% wszystkich pakietów w dumpie. Wygląda groźnie, ale co to dokładnie znaczy?
Najkrócej, oznacza to, że odbiornik nie był w stanie opróżniać bufora, do którego stos TCP wrzucał odebrane z serwera dane. Żeby nie dopuścić do katastrofy, kiedy bufor się zapełnia, stos TCP klienta informuje serwer, żeby się wstrzymał z wysyłaniem następnych danych do czasu opróżnienia bufora. A ponieważ TCP Window (czyli liczba bajtów, po których wymagany jest pakiet z flagą ACK) jest znacznie większe niż segment danych w pakiecie (payload), to serwer może nie zareagować natychmiast i zamiast jednego powiadomienia trzeba ich wysłać kilka lub kilkanaście.
Sprawdźmy teraz, jak długo tak się działo. Pierwszy sygnał od klienta o pustym buforze (Zero Window Size) był w pakiecie 323, co widać na powyższym rysunku. Pakiet miał czas względny 1.183 s. Ustawiam te wartość jako referencję.
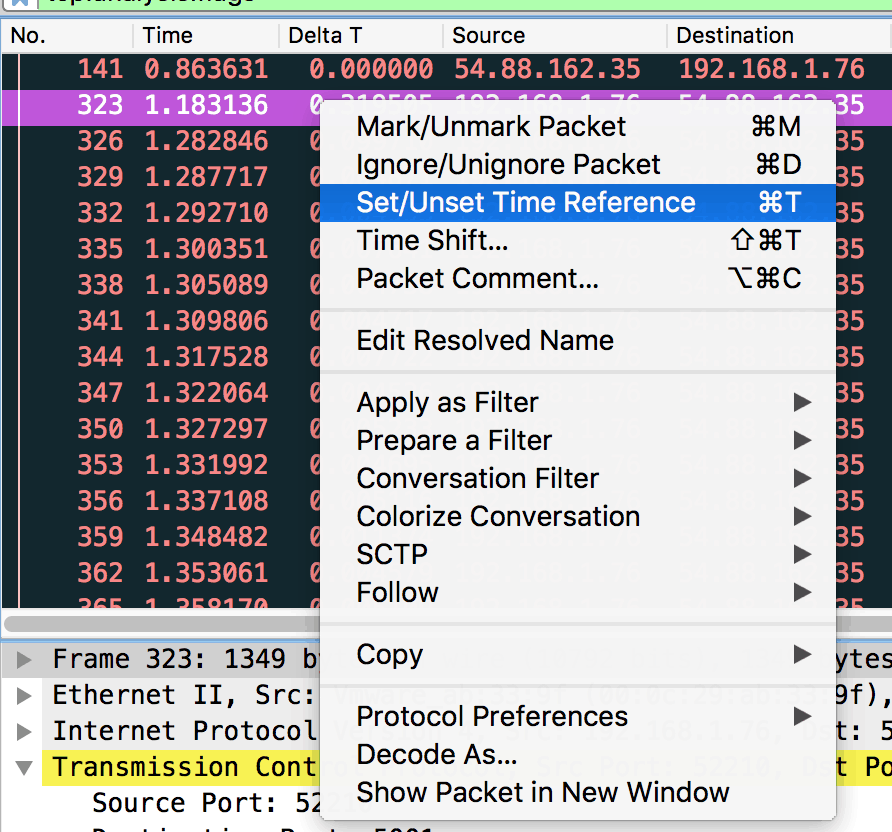
Zdejmuję filtr TCP problems i szukam pierwszego pakietu, w którym jest kontynuacja transferu danych. Inaczej, pierwszy pakiet, jest w kierunku serwera, a dokładniej jego czas względem referencyjnego to czas na rozładowanie bufora odbiorczego. Ten pakiet ma numer 415, a czas widać w kolumnie Time.
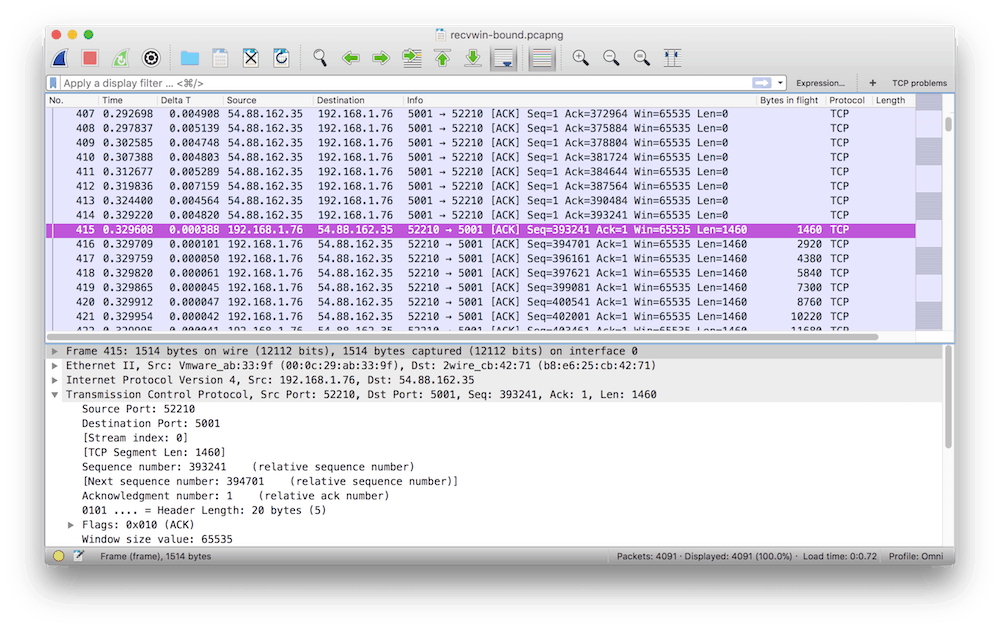 Klient potrzebował prawie 330 ms na wyczyszczenie swojego bufora. Biorąc pod uwagę, że cały dump trwa 10.76 s, a sytuacja zapełnienia bufora wystąpiła wielokrotnie (zaraz policzymy), to mogło to mieć negatywny wpływ na odczucia użytkownika. Sprawdźmy, ile razy to się zdarzyło w ciągu tych niespełna 11 sekund. Można zrobić to elegancko, eksportując dane np. do arkusza kalkulacyjnego, a można policzyć na piechotę. Do tego celu zastosowałem znany już wykres Window Scaling.
Klient potrzebował prawie 330 ms na wyczyszczenie swojego bufora. Biorąc pod uwagę, że cały dump trwa 10.76 s, a sytuacja zapełnienia bufora wystąpiła wielokrotnie (zaraz policzymy), to mogło to mieć negatywny wpływ na odczucia użytkownika. Sprawdźmy, ile razy to się zdarzyło w ciągu tych niespełna 11 sekund. Można zrobić to elegancko, eksportując dane np. do arkusza kalkulacyjnego, a można policzyć na piechotę. Do tego celu zastosowałem znany już wykres Window Scaling.
Wyszło mi 28. Tak więc, 28 x 0,3 s = 8,4 s. W idealnych warunkach, bez ograniczeń co do wielkości buforów czy przepustowości sieci, cały ten transfer przy dostępnym paśmie sieciowym mógłby trwać zaledwie 10,7 – 8,4 = 2,3 sekundy! A gdyby odliczyć od tego marudne zakończenie sesji TCP, które trwało prawie 0,5 sekundy, całość trwałaby jeszcze krócej.
Wniosek jest taki: zanim zaczniesz szukać dziury w całym (tzn. w sieci), upewnij się, że konfiguracja serwera i aplikacja są optymalne. I tym optymistycznym akcentem zakończę zmagania z powolnym transferem.
W następnych części spróbujemy połączyć więcej elementów w całość. Stay tuned.