Zgodnie z obietnicą, wracamy z zapowiadanym tematem mapping w Elasticsearchu. Mapping to podstawowe zagadnienie dotyczące indeksów Elasticsearch, dlatego każdy omnibus powinien umieć sobie z nimi radzić.
Mapping – definicje
Elasticsearch definiuje mapping jako proces określania w jaki sposób dokument i jego pola będą zapisywane i indeksowane. Dla zobrazowania, można go porównać z tworzeniem schematu SQL w relacyjnej bazie danych, tzn. definiowaniem typu każdego z pól rekordu. Np.:
- Które pole zawiera datę, które liczbę, a które ciąg znaków?
- Jaki jest prawidłowy format daty w moich dokumentach?
- Czy pole tekstowe powinno być traktowane jako pole typu text czy keyword (pole analizowane lub nie)?
Ważne jest to, że każdy indeks ma jedno mapowanie i raz utworzone mapowanie danego pola nie może być zmienione bez przeindeksowania dokumentów do nowego indeksu. Elasticsearch dysponuje kilkoma typami danych, w tym:
- Typy proste
o text
o double
o boolean itp.; - Typy obiektowe wspierające notację JSON, takie jak object, lub obiekt zagnieżdżony (nested);
- Typy specjalistyczne, takie jak np. geo_point, reprezentujący współrzędne geograficzne.
Indeksowanie tekstu
Jeśli chcemy dodawać do naszej bazy dokumenty tekstowe – a najprawdopodobniej chcemy – to musimy wiedzieć przede wszystkim, że możemy dodać je jako typ text, lub jako keyword. Pole typu text jest polem analizowanym, czyli przed zaindeksowaniem zostaje przepuszczone przez analizator – o analizatorach opowiemy w osobnym wpisie – który rozbija całe wiersze na pojedyncze tokeny, np. słowa, a dopiero później indeksuje poszczególne tokeny. Pozwala to na wyszukiwanie pełnotekstowe po pojedynczych słowach, a nie po całych frazach. Typ keyword, jak można się domyślić, będzie po prostu zaindeksowanym całym wyrażeniem, a wyszukanie czegoś w polu typu keyword odbywa się poprzez podanie dokładnej wartości (oczywiście zawsze możemy skorzystać z regexów lub pola typu _all).
Jeśli pole typu text dostarcza nam więcej możliwości, to po co w ogóle korzystać z typu keyword? Pole keyword będzie przydatne podczas agregacji całych wyrażeń, sortowania czy np. filtrowaniu. Pola typu text nie są zazwyczaj używane do sortowania czy do agregacji, chociaż są wyjątki.
Przejdźmy teraz do pisania naszego pierwszego mapowania. Zacznijmy od czegoś prostego, z kilkoma polami.<br>PUT products_with_mapping<br>{<br>"mappings": {<br>"products": {<br>"properties": {<br>"name": { "type": "keyword" },<br>"price": { "type": "double" },<br>"category": { "type": "text" },<br>"creation_date": {<br>"type": "date",<br>"format": " basic_date_time"<br>}<br>}<br>}<br>}<br>}<br>
Dodaliśmy do naszego nowego indeksu mapowanie, które definiuje typy nazwy, ceny, kategorii, a na końcu mówi, że data utworzenia tego produktu musi być w formacie basic_date_time czyli w tym przypadku yyyyMMdd'T'HHmmss.SSSZ.
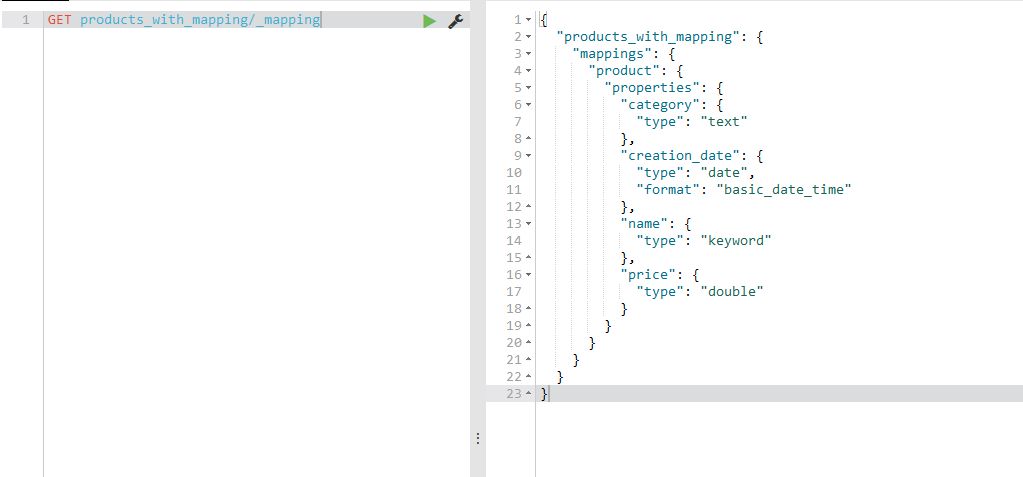
Żeby sprawdzić, czy Elasticsearch widzi nasze mapowanie, wystarczy wpisać w konsoli:
GET products_with_mapping/_mapping
Powinniśmy otrzymać w odpowiedzi nasz mapping, wyglądający mniej więcej tak:
Proste, prawda? W następnej części porozmawiamy o tym, co się dzieje, gdy dodajemy dokument bez mapowania, a on i tak zostaje zapisany z pewnym typem i jak kontrolować tę magię.