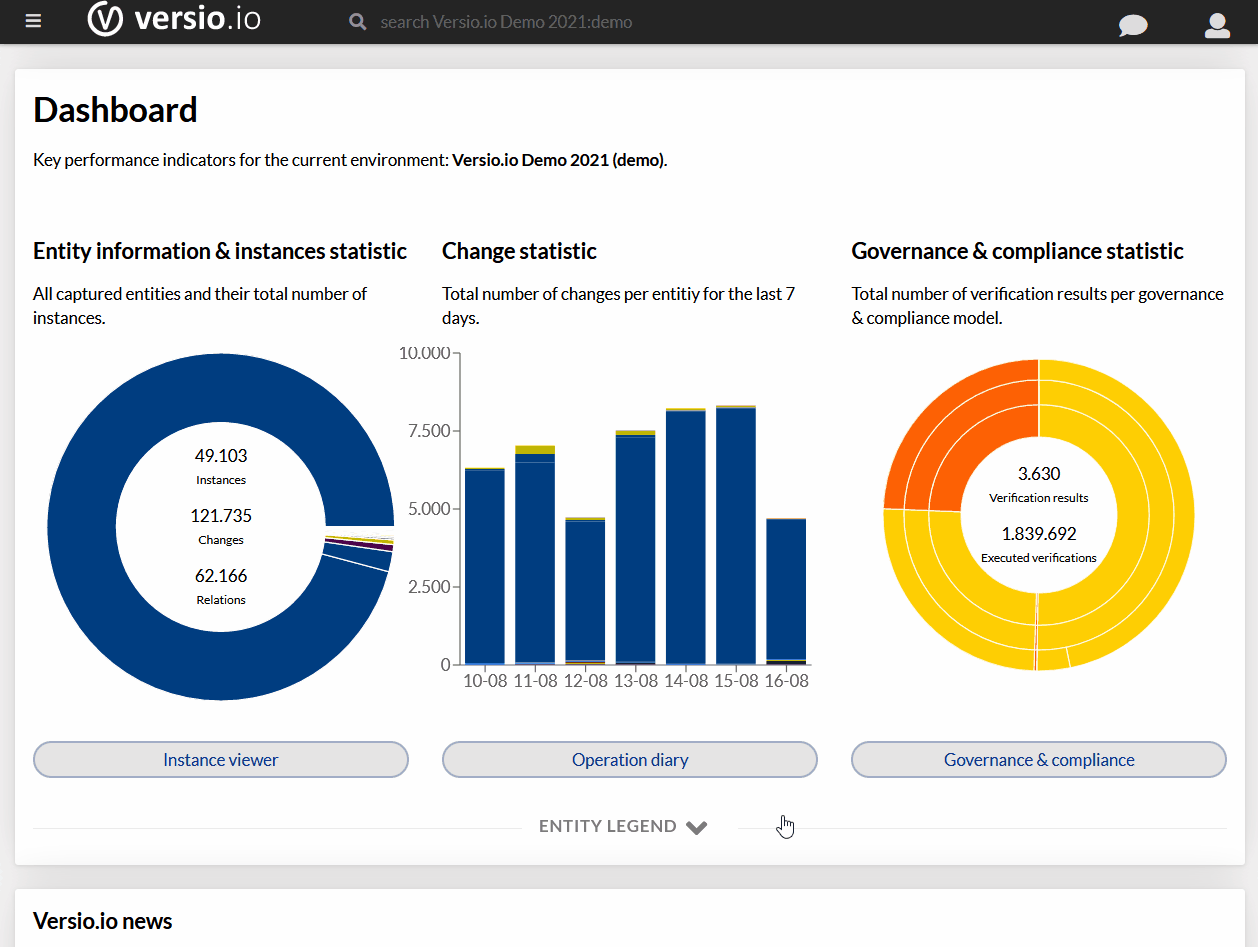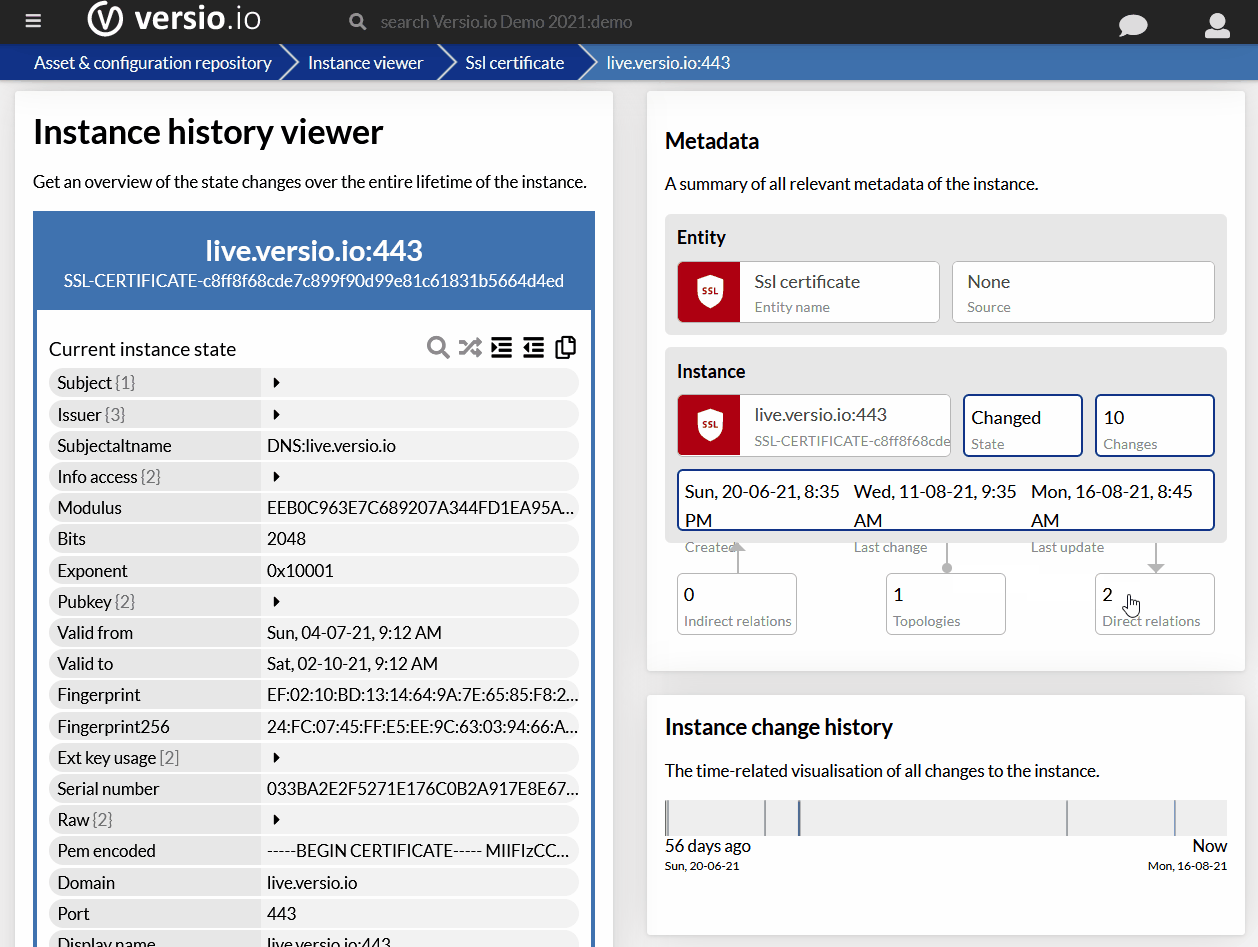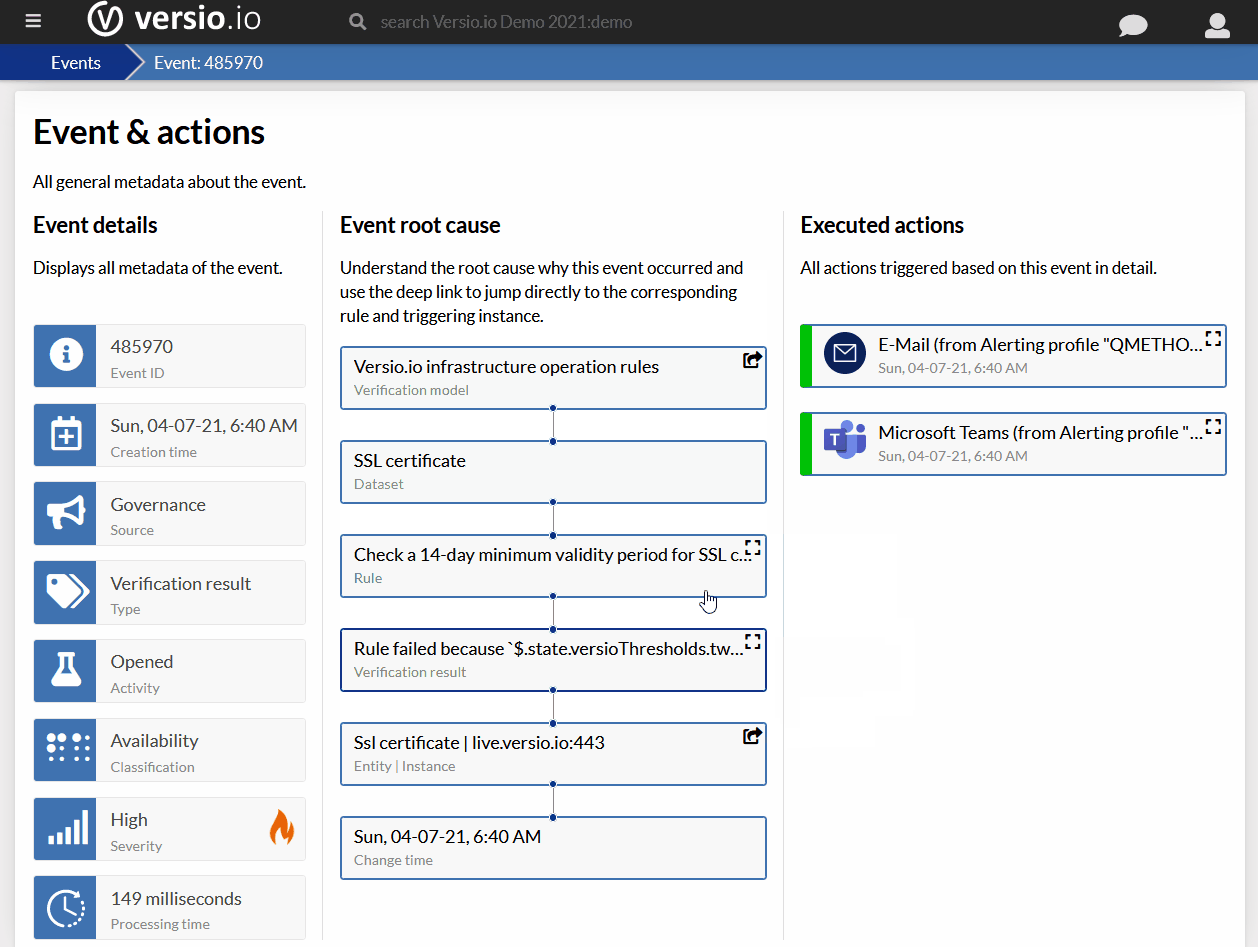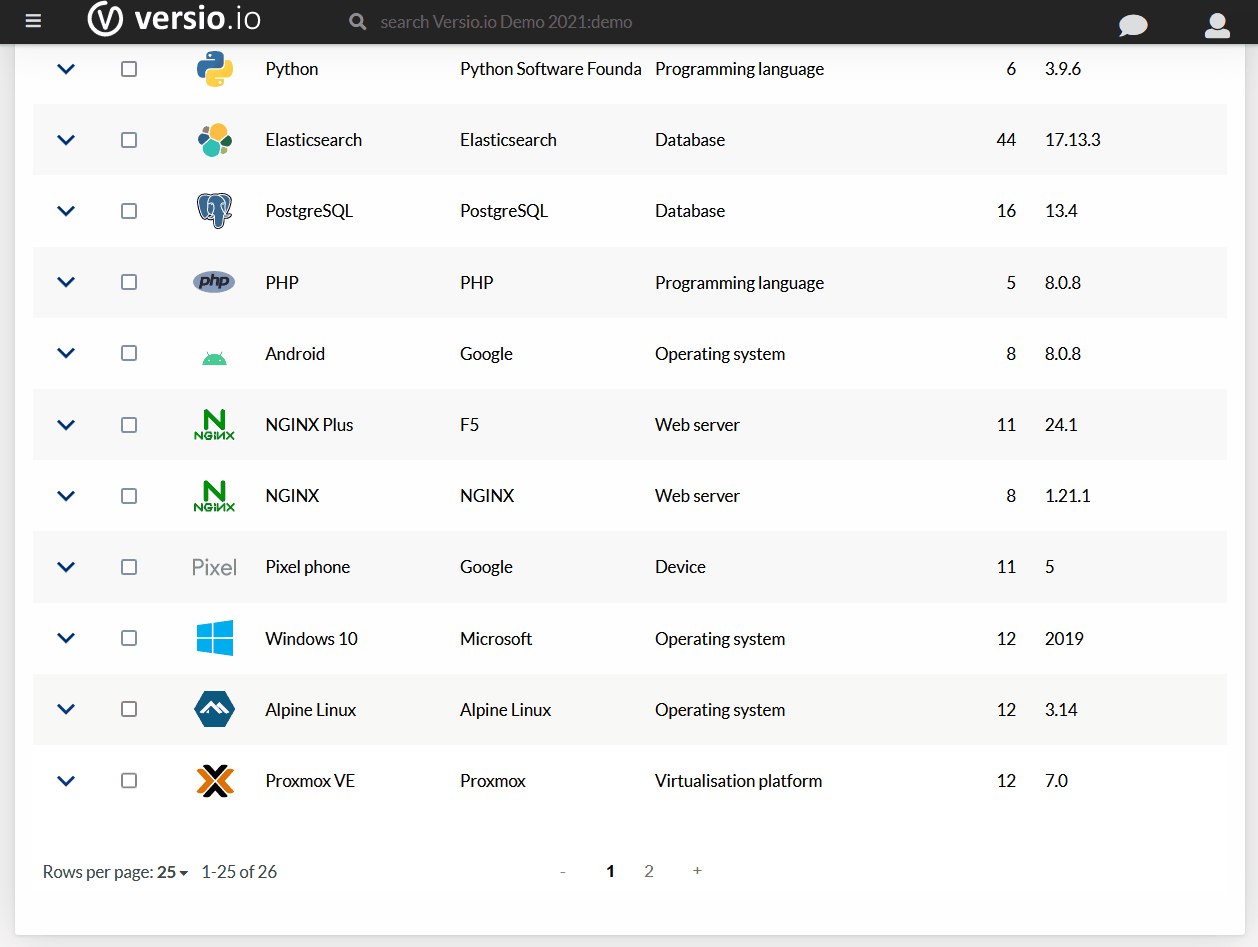
Zgodnie z obietnicą, dziś na warsztat idzie Kibana. W zasadzie już ją masz, jeśli idziesz ze mną od początku. Kibana, a właściwie jej konsola, była potrzebna do testowania Elasticsearcha, ale dla porządku – a każdy omnibus ma wszystko w jak najlepszym porządku – instalator pobierasz ze strony https://www.elastic.co/downloads/kibana. Po rozpakowaniu archiwum, uruchamiasz ją z katalogu $KIBANA_INSTALL/bin. Zależnie od systemu, albo ./kibana, albo kibana.bat, jeśli używasz Windows. W przypadku pomyślnej instalacji i komunikacji z Elasticsearchem, twój terminal może wyglądać podobnie do mojego.
Bez wchodzenia w szczegóły, Kibana startuje jako serwis HTTP na porcie 5601. Możesz to szybko sprawdzić:
http://localhost:5601
i Kibana zaprosi cię do ustawienia nazwy lub wzorca nazwy indeksu.
Wpisz tam, co chcesz, ale jeśli chcesz lecieć ze mną torem ustalonym w poprzednich częściach ELK-owego bloga, to sugeruję następujący wzorzec: logstash-apache-*
Zaraz po zdefiniowaniu wzorca indeksu (nie zapomnij wcisnąć Create ???? ), możesz sprawdzić, czy i co Kibana zobaczyła w Elasticsearchu.
Co dalej? Pola indeksu możesz:
1. przefiltrować, bo indeksy mogą zawierać setki pól,
2. sortować dane wg klucza pola (rosnąco i malejąco, klikając w nagłówek tabeli),
3. sprawdzić atrybuty pola,
4. zmienić format wyświetlania danych (w ograniczonym zakresie).
Stworzenie indeksu powoduje przejście do sekcji Discover. Tu można przeglądać surowe dane (zapewniam, mało ekscytujące), ale pewnie i tak niewiele zobaczysz, bo domyślny zakres czasu to ostatnie 15 minut.
A jeśli logi Apache, stworzone przez Fake Log Generator, powstały kilka godzin czy dni temu, to musisz poszerzyć zakres (w prawym górnym rogu ekranu) do takiej wielkości, żeby załapały się dane z logów.
Dzięki temu zabiegowi zobaczysz, mam nadzieję, to co zostało stworzone przez Fake Log Generator, a dodatkowo Kibana pokaże na osi czasu, kiedy i jak wiele dokumentów zostało dodanych do indeksu.
Poniżej osi czasu masz przegląd zawartości dokumentów, a dla każdego rekordu można dodatkowo przejrzeć pola i ich typy, żeby łatwo wybrać te, które zostaną użyte do wizualizacji zgromadzonych danych. Strzałką zaznaczona jest nazwa indeksu, do którego wpadają dane z Logstasha. Do wizualizacji możesz wybrać takie pola, jakie tylko chcesz.
No i teraz zaczyna się najciekawsza część – FANFARY! – wizualizacja. Idziemy do sekcji Visualize. No i, niestety, tu możesz poczuć pierwsze rozczarowanie. Chciałoby się, żeby Kibana automatycznie wybrała jakieś sensowne dane i pokazała pierwszy wykres. A tu znowu, niestety, trzeba coś wybierać. Na szczęście, nie jest to skomplikowane.
Na potrzeby tego ćwiczenia, klikam Vertical bar chart i od razu muszę odpowiedzieć na pytanie, skąd pobrać dane. To może być albo nowe wyszukiwanie w indeksie, albo już istniejące, wcześniej zapisane. Ponieważ o kryteriach wyszukiwania i ich zapisywaniu nie było dotąd mowy, odkładam to na później, bo wrócimy do tego. Wybieram nowe wyszukiwanie z indeksu.
Dobra, mamy źródło danych, więc pozostaje tylko rozłożenie ich na osiach wykresu. Niestety, Kibana niczego za ciebie nie zrobi. Ale nie jest to trudne i w większości widgetów wygląda bardzo podobnie, dlatego omówię to dokładniej.
Najpierw wybieramy metrykę, której wartości pokażą się na osi OY. I tu niespodzianka, bo Kibana sama wybrała, co było dostępne i zastosowała metrykę Count, czyli w naszym przypadku liczba wpisów w logach (liczba dokumentów).
Teraz na oś OX musimy wybrać czas. Ponieważ zakres czasu, który zmienialiśmy na wstępnie wciąż obowiązuje (u mnie – tydzień), to wybieram agregację Date Histogram (histogram na osi czasu, z domyślnym interwałem Auto(matycznym). Taki interwał jest wyliczany w zależności od zakresu czasu analizowanych danych; tyle wystarczy. Naciskam guzik Apply changes, żeby Kibana narysowała piękny wykres.
Twój pewnie będzie wyglądał inaczej, ważne jest to, że coś się na tym wykresie pojawiło. Pamiętaj, że agregacja typu Date Histogram ma sens dopiero wtedy, kiedy mamy dane z co najmniej dwóch dni, inaczej Kibana będzie się burzyć i niczego nie narysuje.
Oczywiście, możesz dodać więcej metryk używając przycisku Add metrics oraz ustalić inne poziomy agregacji, ale tym zajmiesz się później.
Teraz trzeba zapisać nowo stworzoną wizualizację. Konwencja nazewnictwa nie jest ustalona, ale dobrze jest trzymać się jakiegoś schematu – w tym przypadku w nazwie będzie typ użytej metryki, czyli count. Zapisuję wizualizację za pomocą polecenia Save (u góry ekranu) pod nazwą Log_count, a nuż się przyda w przyszłości.
A tymczasem się ściemnia i trzeba kończyć na dziś. Udało się przekonać Kibanę od pobrania danych z indeksu utworzonego na bazie danych z Logstasha i narysować nieprzeciętnej urody wykres.
A w następnym odcinku sprawdzimy, jakie inne ciekawe widgety mamy do dyspozycji i jak manipulować danymi, żeby osiągnąć efekt WOW!