W części 4 wzięliśmy na warsztat wpływ wielkości TCP Window stosu TCP na szybkość transferu danych przez sieć. Wspomniałem tam o mechanizmie TCP slow start. Dziś parę słów wyjaśnienia, co to jest i dlaczego działa tak, jak działa. I po co to zostało wymyślone.
TCP slow start
Mechanizm ten służy temu, żeby sesja transferu danych przez sieć dopasowała się do istniejących warunków (opóźnienie i przepustowość łącza) i optymalnie wykorzystała dostępne zasoby. Transfer rozpoczyna się na niskim poziomie bloku danych i po każdym pomyślnie przesłanym segmencie jest on powiększany, aby maksymalnie wykorzystać możliwości przesyłowe sieci. Takie zachowanie zapobiega przesyceniu (oversaturation) łącza. Przesycenie łącza skutkuje zatorem w sieci, a to w końcowym efekcie oznacza znacznie wolniejszy przesył danych niż przy wolnym starcie.
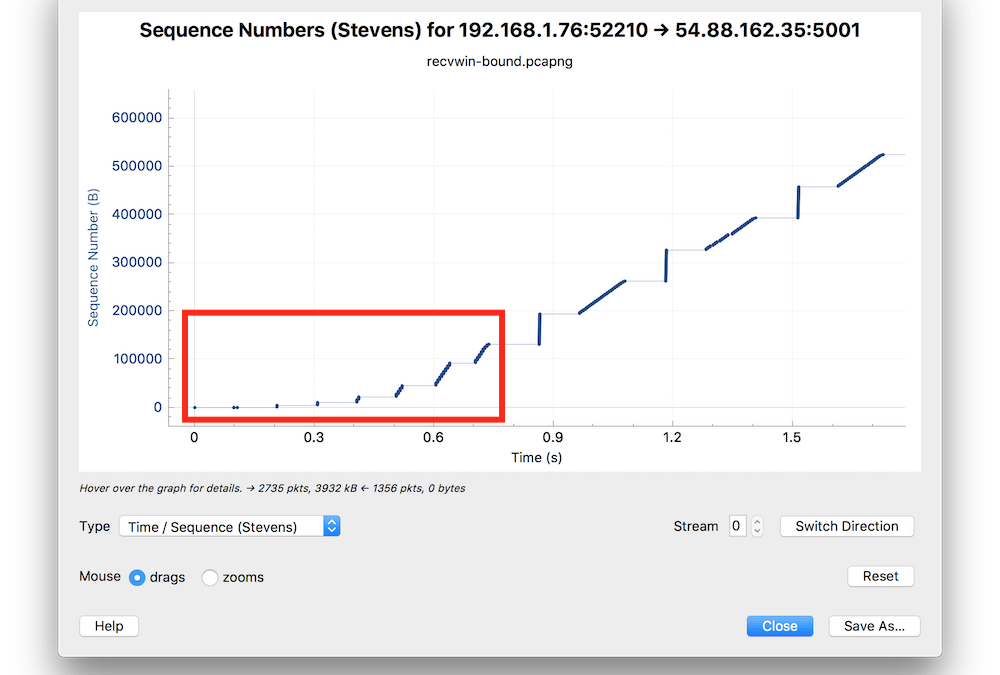
Jak rozpędza się transmisja między dwiema stacjami, widać świetnie na diagramie Time Sequence z dumpa, którego używałem do ilustracji problemów z TCP Window.
 Przez pierwsze ok. 0,75 s transfer rozpoczyna się stosunkowo wolno, właśnie aby nie przesycić łącza sieciowego. Stos TCP posiada wewnętrzny parametr zwany Congestion Window (CWD). Zwykle wielkość CWD zaczyna się od 2 (liczba pakietów wysyłanych bez potwierdzenia), a potem jest powiększana w miarę jak przesyłane pakiety zostaną potwierdzone.
Przez pierwsze ok. 0,75 s transfer rozpoczyna się stosunkowo wolno, właśnie aby nie przesycić łącza sieciowego. Stos TCP posiada wewnętrzny parametr zwany Congestion Window (CWD). Zwykle wielkość CWD zaczyna się od 2 (liczba pakietów wysyłanych bez potwierdzenia), a potem jest powiększana w miarę jak przesyłane pakiety zostaną potwierdzone.
TCP Slow start nie jest problemem w protokołach do transferu plików, takich jak FTP, albo dla aplikacji wykorzystujących istniejące połączenia TCP (TCP connection reuse). Ale już dla krótkich i częstych konwersacji to może mieć znaczenie. I takim przypadkiem teraz się zajmiemy.
CWD i MSS jako parametry sprawności transferu
Oprócz wartości CWD, istotne znaczenie ma MSS, czyli Maximum Segment Size. MSS określa wielkość bloku danych w pakiecie. Przeważnie MSS ma wartość 1460, ale może być zmniejszana w celu przekazywania nagłówków VPN czy na potrzeby specjalnych protokołów. Na poniższym obrazku Wireshark pokazuje MSS jako pole o nazwie tcp.len.

CWD wpływa na liczbę pakietów przesyłanych przez stos TCP bez potwierdzenia. Czyli po wysłaniu każdej paczki pakietów musi przyjść potwierdzenie w postaci pakietu ACK.

To powiększanie CWD nie trwa bez końca i jest wstrzymywane w momencie, gdy:
• Osiągnięto wielkość TCP Window obiorcy (klienta)
• Wykryto zator, bo doszło do utraty pakietów (packet loss)
• Osiągnięto maksymalny rozmiar bloku zapisu, co wynika z konfiguracji aplikacji.
Natomiast mały MSS wymusza większą liczbę pakietów ACK, czyli w połączeniu ze znacznym opóźnieniem łącza sieciowego, np. rzędu 200-300 ms, co nie jest rzadkością przy łączach internetowych, da w rezultacie istotne wydłużenie transferu danych.
Konfiguracja stosu TCP ma znaczenie, sieć niekoniecznie
Wyobraź sobie, że mamy typowy przypadek strony webowej składającej się z 30 komponentów (HTTP hits) o średnim rozmiarze 100 kB. Zakładam, że jest to jedna ze stron twojej aplikacji webowej, która jest napisana optymalnie (no, prawie ).
Wyobraź sobie teraz, że twoja optymalnie napisana aplikacja webowa jest serwowana przez bardzo nieoptymalnie skonfigurowane proxy. Innymi słowy, twoje proxy jest skonfigurowane niewłaściwie i nie potrafi używać tzw. TCP persistent connection. Efekt jest taki, że stos TCP musi nawiązać 30 sesji TCP, żeby załadować tę stronę. Każda sesja TCP rozpoczyna się wolnym startem, a to może oznaczać, że pomimo łącza internetowego o wielkiej przepustowości, strona będzie ładować się bardzo wolno. Wnioski wyciągniesz samodzielnie, ja tylko mogę ci podpowiedzieć, jakie tematy poruszyć z adminami czy sieciowcami.
1. Persitent TCP connections – jeśli to możliwe, korzystaj z tego, bo takie ustawienie minimalizuje TCP slow start. Sesję TCP trzeba kiedyś zacząć, ale im rzadziej to się dzieje, tym mniejszy wpływ Slow start na czas przesyłania danych przez sieć.
2. Congestion Window size – load balancery czy proxy pozwalają na konfigurację CWD. Zwiększenie wartości CWD pozwala zminimalizować liczbę TCP turns (czyli par pakiety z danymi + pakiet potwierdzenia ACK), a w ten sposób znacznie lepiej wykorzystać pasmo sieciowe w łączach o dużym opóźnieniu.
Z drugiej strony, nawet jeśli łącze ma spore opóźnienie, nie musi to koniecznie oznaczać, że transfer będzie wolny. Jeśli protokół sieciowy nie jest gadatliwy, tj. nie wymaga bardzo dużej liczby tzw. turns (dane-potwierdzenie) na pojedyncze TCP Window, to takie łącze o dużej przepustowości może być świetnie wykorzystane i opóźnienie nie będzie zauważalne z punktu widzenia użytkownika.
Co sprawdza się w sieciach LAN, gdzie opóźnienie sieci jest niewielkie, niekoniecznie będzie dobrze działać w Internecie, na łączach WAN. Tam o opóźnieniu decyduje fizyczna odległość, nośnik sieci, czyli medium (np. łącze satelitarne), a także liczba tzw. hopów. Im więcej stacji przesiadkowych jest na drodze pakietów między klientem a serwerem, tym większe prawdopodobieństwo, że aplikacja będzie działać wolno. Sprawdź sobie, ile jest hopów między serwerem twojej aplikacji, którą uruchamiasz w publicznej chmurze a twoim komputerem. Jeśli nigdy cię to nie interesowało, uruchom program traceroute (Unix/Linux) lub tracert (Windows). W oknie twojego terminala wpisz takie polecenie:
$ traceroute gigabitmonitor.com
gdzie gigabitmonitor.com to nazwa DNS serwera aplikacji, którą chcesz sprawdzić. Ja akurat chcę sprawdzić moją odległość od serwera aplikacji, która ilustruje dostępność do szerokopasmowego Internetu, albo inaczej, dostępność łącz o przepustowości 1 Gbps.
U mnie wygląda to tak:
1 router (192.168.88.1) 10.571 ms 0.869 ms 0.949 ms<br>2 192.168.1.20 (192.168.1.20) 1.748 ms 1.551 ms 1.437 ms<br>3 ns1.abc.pl (91.122.214.1) 5.072 ms 9.195 ms 4.395 ms<br>4 193.26.131.53 (193.26.131.53) 5.451 ms 5.354 ms 4.589 ms<br>5 ae4-3101.cr1-waw1.ip4.gtt.net (46.33.90.125) 11.494 ms 10.335 ms 9.909 ms<br>6 xe-1-0-0.cr3-fra2.ip4.gtt.net (89.149.186.182) 41.109 ms 33.641 ms<br>xe-9-0-4.cr3-fra2.ip4.gtt.net (89.149.135.110) 32.174 ms<br>7 tinet-up.bb-a.fra3.fra.de.oneandone.net (213.200.65.202) 33.187 ms 32.664 ms 32.634 ms<br>8 ae-10-0.bb-a.bap.rhr.de.oneandone.net (212.227.120.147) 38.821 ms 38.722 ms 38.637 ms<br>9 ae-1.gw-distp-a.kw.nbz.fr.oneandone.net (195.20.243.3) 37.059 ms 36.718 ms 37.095 ms<br>10 ae-1.gw-prtr-a0204-a.kw.nbz.fr.oneandone.net (195.20.243.72) 38.163 ms 59.029 ms 50.018 ms<br>11 s19023689.onlinehome-server.info (82.165.134.64) 41.381 ms 38.084 ms 38.373 ms |
Jak to czytać? Nic szczególnie trudnego.
Z mojego laptopa do serwera jest 11 hopów (pierwsza kolumna), a to oznacza, że pakiety mają 10 stacji przesiadkowych (druga kolumna) na routerach, zanim dotrą do serwera. Czy to dużo? Nieszczególnie. O wiele ważniejsze od liczby hopów jest opóźnienie (kolumny 3-5), które jest wprowadzane przez kolejne łączą providerów. Czasy w ostatnich trzech kolumnach to round trip time (RTT) do każdego z urządzeń.
W powyższym przykładzie widać, że wszystkie urządzenia na trasie do serwera odpowiadają na pakiety ICMP ECHO, które są używane przez traceroute. Ale może zdarzyć się sytuacja, że zamiast czasów sypnie śniegiem, jak niżej.
$ traceroute wakacje.pl<br>traceroute to wakacje.pl (212.77.99.88), 64 hops max, 52 byte packets<br>1 router (192.168.88.1) 1.824 ms 0.832 ms 0.921 ms<br>2 192.168.1.20 (192.168.1.20) 1.900 ms 1.540 ms 1.531 ms<br>3 ns1.abc.pl (91.122.214.1) 10.192 ms 12.913 ms 22.568 ms<br>4 193.26.131.53 (193.26.131.53) 15.083 ms 9.827 ms 10.676 ms<br>5 wirtualna-polska.tri-ix.net (194.116.131.107) 8.767 ms 14.341 ms 22.891 ms<br>6 rtr4.rtr-int-2.adm.wp-sa.pl (212.77.96.77) 11.360 ms 9.252 ms 9.594 ms<br>7 * * *<br>8 * * *<br>9 * * *<br>10 * * *<br>11 * * *<br>12 * * *<br>13 * * *<br>14 * * * |
Nastrój świąteczny, że ho, ho! Ale co te gwiazdki znaczą? Czy to jest jakiś problem? Dla aplikacji, w tym przypadku wakacje.pl, niekoniecznie. Traceroute w ten sposób sygnalizuje, że urządzenie sieciowe na pozycji 7 nie odpowiada na pakiety ICMP ECHO. Być może ma wyłączoną obsługę, być może jest jakiś błąd w stosie TCP tego urządzenia, tego się nie dowiemy. Ale wiadomo, że urządzenie nie odpowiedziało (timeout) na ECHO. Gorzej, jeśli którejś z trzech gwiazdek brakuje, bo to może oznaczać, że pakiety kontrolne przepadły gdzieś po drodze – to oznacza stratność sieci. Ponieważ datagramy ICMP to nie to samo, co TCP, nie można liczyć na retransmisje w przypadku utraconych pakietów.
Całe te dywagacje na temat CWD czy traceroute’a, może niezbyt ekscytujące, są wprowadzeniem do tematu stratności sieci, którym zajmiemy się w następnych odcinkach. Jeśli się podobało, daj mi znać. A może czegoś ci brakuje? Zostaw, proszę, komentarz, chętnie poruszę temat, który cię interesuje. Do następnego.